Friederike Werner von ZEIT Online hat mich eingeladen, ein Wissensquiz zur Wortwahl, insbesondere zur Sprache der Herabsetzung und Ausgrenzung auszudenken.
Die korrekten Antworten und Erläuterungen habe ich auf hassrede.de zusammengestellt.
Friederike Werner von ZEIT Online hat mich eingeladen, ein Wissensquiz zur Wortwahl, insbesondere zur Sprache der Herabsetzung und Ausgrenzung auszudenken.
Die korrekten Antworten und Erläuterungen habe ich auf hassrede.de zusammengestellt.
Das Team von TEDxDresden hat mir dankenswerter Weise die Gelegenheit gegeben, einen Vortrag zum Thema „Schöne neue Algorithmen für die Black Box Mensch“ zu halten. Darin habe ich versucht, aus kulturwissenschaftlicher Perspektive darzustellen, wo die Probleme liegen und was man besser machen sollte, wenn man soziale oder kulturelle Phänomene mit maschinellen Methoden modellieren will.
Ich behaupte, dass die zurzeit gängige Herangehensweise bei der Modellierung sozialer Phänomene einer behaviorischen Vorstellung vom Menschen folgt, und plädiere statt dessen für Algorithmen, die menschliches Verhalten als interpretiertes Verhalten (und damit immer auch als potentiell mehrdeutig) modellieren sollten.
Das Beispiel, das ich prominent behandle, wird zurzeit auch in einem NZZ-Artikel von Steve Przybilla lobenswert kritisch reflektiert.
Hate Speech ist in aller Munde, und das in doppelter Hinsicht: Einerseits flutet ein Tsunami an Hasskommentaren das Internet und untergräbt in den Augen vieler die Fundamente der demokratischen Meinungsbildung. Andererseits erleben wir, wie Hate Speech auch im öffentlichen Diskurs zu einer eigenständigen Kategorie der verbalen Herabsetzung wird. Ein Indiz dafür ist der Anstieg des Gebrauchs einschlägiger Lexeme in SPIEGEL Online in den letzten zwei Jahren (bis 8/2016). Neben dem Ausdruck der „Volksverhetzung“, der einen Straftatbestand bezeichnet, ist die Anzahl der Nutzung der Ausdrücke „Hetze“, „Hetzer“ und „hetzerisch“ sowie von „Hassbotschaft“ und „Hasskommentar“ im Ressort Innenpolitik deutlich gestiegen:

Auffällig ist freilich, dass das Wort „Hetze“ häufiger verwendet wird als das Englische „Hate Speech“ und seine Lehnübersetzung „Hassrede“. Im Ressort Netzwelt freilich haben Komposita mit dem lexikalischen Morphem /hass/ wie „Hassbotschaft“, „Hasskommentar“ oder „Hassposting“ den Ausdruck „Hetze“ im Jahr 2016 noch überholt. Und auch die Bezeichnungen „Hate Speech“ und „Hassrede“ kommen deutlich häufiger vor, als in den Jahren vor 2015.

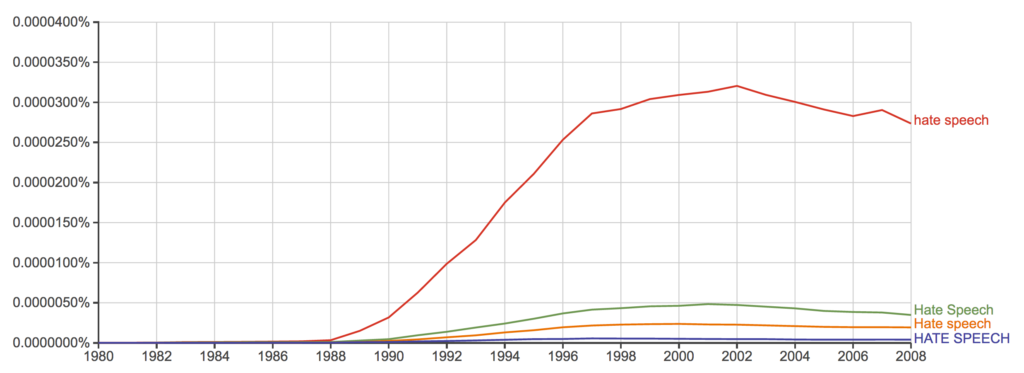
Die Analyse zeigt, dass der Ausdruck „Hate Speech“ und seine Lehnübersetzung „Hassrede“ sowie davon semantisch inspirierte Komposita wie „Hassbotschaft“ – und mit ihnen Hassrede als spezifische Form verbaler Herabsetzung – im Kontext von Netzdiskursen geprägt wird. Im Englischen, in dem sich die Bedeutung von „Hate Speech“ auch aus der semantischen Nähe zu „Hate Crime“ (einem Delikt gegen ein nach dem Kriterium der vermeintlichen Zugehörigkeit zu einer gesellschaftlichen Gruppe ausgewählten Opfer) speist, ist der Ausdruck schon länger eingeführt, wie ein Blick auf die Daten im Google n-Gram-Viewer belegen.
Trotz aller Kritik am Begriff der Hassrede und trotz der heftigen Diskussionen darüber, wie mit Hate Speech in sozialen Medien zu verfahren sei, hat es den Anschein, dass es den Kritiken (noch) nicht gelungen ist, den Begriff negativ im Sinn einer undemokratischen Redeverbotsideologie zu besetzen, wie dies beim Ausdruck „politische Korrektheit“ der Fall ist.
So spielt zwar auch in den Online-Publikationen des berüchtigten Kopp Verlag (hier ausgewertet: info.kopp-verlag.de) die Beschäftigung mit dem Thema eine immer größere Rolle. Dennoch wird hier dominant von „Hetze“ gesprochen, als „Hate Speech“ oder „Hassrede“ wird das Thema erst seit 2016 geframet.

Auch wenn der Satz „Truth – The New Hate Speech“ also in Deutschland (noch) nicht sinnvoll sagbar ist, zeigen die von den Wortfamilien der Morpheme /hetze/ und /hass/ bezeichneten Sachverhalte bei SPIEGEL Online und im Kopp Verlag nur geringe Schnittmengen, was auf eine lagerspezifische strategische Instrumentalisierung der Begriffe hindeutet.
Der folgende Graph zeigt Komposita mit dem lexikalischen Morphem /hass/ in den Korpora von info.kopp-verlag.de und SPIEGEL Online 2015 und 2016. Rot markiert sind Komposita, die sich ausschließlich beim Kopp Verlag fanden. Grau sind Komposita, die nur im Korpus von SPIEGEL Online vorkommen. Schwarz dargestellte Komposita finden sich in beiden Korpora.

Während der Kopp-Verlag vom „Leser-Hass“ und „Deutschland-Hass“ schreibt und damit auf patriotische „Mainstream-Presse“-Verächter zielt, thematisiert SPIEGEL Online den Medienhass, also den Hass auf die Medien. Entsprechend werden viele Determintativkomposita mit /hass/ als Erstglied in Kontexten verwendet, in denen über die Bestrebung zur Ächtung von Hate Speech als staatliche Propaganda- und Zensurmaßnahme berichtet wird; oder sie bezeichnen Sachverhalte, die mit dem muslimischen Glauben im Zusammenhang stehen („Hass-Moschee“).
Die gleiche Tendenz ist bei Komposita mit dem lexikalischen Morphem /hetze/ beobachtbar. Hier wird beim Kopp-Verlag die Selbstviktimisierung der Neuen Rechten („AfD-Hetz“, „Medienhetze“) und die Freundschaft zu Russland („Kriegshetze“ westlicher Politiker) sichtbar, aber auch die vermeintliche „Hetzjagd“ auf Kritiker der Flüchtlingspolitik und der „Hetz-Pranger“ der BILD, die Emittenten von Hate Speech in sozialen Netzwerken mit Klarnamen und Foto abgebildet hatte, verweisen darauf, dass man sich selbst und die eigenen Sympathisanten als Opfer eine „Hetzkampagne“ sieht. Bei SPIEGEL Online dominiert dagegen eine Mischung aus Internet- und Flüchtlingsthematik, wenn von „Hetze“ die Rede ist.

In der gegenwärtigen Konjunktur von Wort und Sachverhalt ist der Begriff der Hate Speech umkämpft. Während die begriffliche Unschärfe im Deutschen jede Art der gruppenbezogenen Beleidigung als Hate Speech deutbar macht und so die Extension des Begriffs auf viele Phänomene ausweitet, die im wissenschaftlichen Diskurs nicht als Hate Speech gelten würden, wird von anderer Seite versucht, den Begriff umzudeuten in ein Instrument der Unterdrückung freier Meinungsäußerung und Zensur. Ob dies gelingt dürfte wesentlich auch davon abhängen, ob es gelingt, im öffentlichen Diskurs eine verständliche und handhabbare Bedeutung von „Hate Speech“ zu konturieren, die nicht leicht als Ressource zum Ausschluss missliebiger Positionen missbraucht werden kann, sondern Formen sprachlicher Herabwürdigung benennt und ächtet, die gruppenbezogen sind und deren herabwürdigende Kraft sich aus als unveränderlich gedachten Zuschreibungen an die Vertreterinnen und Vertreter dieser Gruppe speist.
(Erstmals publiziert auf hassrede.de)
Die AfD wehrt sich heftig gegen die Zuschreibung, rechtspopulistisch zu sein. Sie sucht die Schuld dann bei den Medien, die zu bequem seien, sich mit den Inhalten auseinanderzusetzen, und scheut auch nicht vor persönlichen Diffamierungen von Wissenschaftlern zurück, die Inhalte und Politikstil der AfD als „populistisch“ bezeichnen. Für eine Tagung der Arbeitsgemeinschaft Sprache in der Politik habe ich die Sprache der AfD daraufhin untersucht, ob sich in ihr Merkmale finden, die es rechtfertigen, die AfD als populistische Partei zu bezeichnen oder ob die Zuschreibungen der Presse unbegründet sind.
In der politikwissenschaftlichen Debatte lassen sich grob zwei Traditionslinien der Definition von „Populismus“ ausmachen:
Datengrundlage
Die Datengrundlage für die im folgenden kurz zusammengefassten Ergebnisse, waren die Pressemitteilungen und Wahlprogramme von sieben Parteien, die sich um Mandate im Landtag in Rheinland-Pfalz bewerben.
Das Korpus der Wahlprogramme setzte sich wie folgt zusammen:
| Partei | wordcount |
|---|---|
| AFD Wahlprogramm | 9863 |
| CDU Regierungsprogramm | 28322 |
| FDP Landtagswahlprogramm | 36163 |
| Grüne Landtagswahlprogramm | 44582 |
| Die Linke Landtagswahlprogramm | 21523 |
| NPD „10 Punkte“ | 1727 |
| SPD Regierungsprogramm | 21746 |
Neben Wahlprogrammen habe ich auch die auf den Webseiten der Parteien veröffentlichten Pressemitteilungen und Stellungnahmen analysiert, die als autorisierte Meinungsäußerungen ebenfalls die Haltung des jeweiligen Landesverbands zu einem politischen Thema repräsentieren.
| Partei | wordcount | no. of texts |
|---|---|---|
| AfD Rheinland-Pfalz | 57964 | 237 |
| CDU Rheinland-Pfalz | 74283 | 261 |
| FDP Rheinland-Pfalz | 27648 | 73 |
| Gruene Rheinland-Pfalz | 241876 | 914 |
| Die Linke Rheinland-Pfalz | 154179 | 509 |
| NPD Rheinland-Pfalz | 63894 | 174 |
| SPD Rheinland-Pfalz | 22221 | 93 |
Skandalisierung
Um zu untersuchen, ob der Politikstil der AfD mehr als der anderer Parteien von Skandalisierungen geprägt ist, habe ich die Distribution einer Reihe von Merkmalen in den Pressemitteilungen aller Parteien gemessen und mit einander in Beziehung gesetzt. Im Einzelnen waren dies:
Für jede dieser funktional und semantisch definierten Wortklassen wurde die relative Frequenz in jedem Korpus berechnet und die Differenz zur relativen Häufigkeit in der Summe aller anderen Korpora bestimmt.
Die Analyse zeigt, dass bei der AfD alle untersuchten Indikatoren deutlich überdurchschnittlich häufiger auftreten als in der Summe der anderen Parteien. Keine andere Partei zeigt auf allen Indikatoren so gleichmäßige positive Ausprägungen. Dies erlaubt den Schluss, dass die Pressemitteilungen der AfD stärker emotionalisieren und skandalisieren als die aller anderen Parteien.
Rekurs auf das Volk
Die AfD in Rheinland-Pfalz vertritt — anders als andere Landesverbände — keine offen völkische Ideologie. Die Konstruktion einer deutschen Eigengruppe erfolgt durch die im Vergleich zu anderen Parteien überdurchschnittliche Thematisierung der Politikfelder Flüchtlinge, Asyl und Migration. Berechnet man beispielsweise, welche Substantive für die AfD RLP im Vergleich zu allen anderen Parteien signifikant sind, werden die thematischen Schwerpunkte deutlich (rot markierte Lexeme):
Die AfD tritt zudem für mehr plebiszitäre Elemente ein. Dies zeigt sich beispielsweise, wenn man die Komposita mit den lexikalischen Morphem /volk/ und /bürger/ in ihrem Wahlprogrammen untersucht. Abgesehen von „Volkswirtschaft“ thematisieren alle Komposita mit /volk/ größere Partizipationsmöglichkeiten der deutschen Staatsbürger.
Volksbeteiligung, Volksentscheid, Volkspartei, Volksbegehren, Volksherrschaft, Volksinitiative, Volksabstimmung, Volkssouveränität, Volkswirtschaft
Ähnlich sieht es bei Komposita mit dem lexikalischen Morphem /bürger/ aus:
Bürgergesellschaft, Mitbürger, Bürgerinteresse, Bürgerentscheid, Bürgertum, Bürgerbüro, Bürgerbeteiligung, Staatsbürgerschaft, bürgerlich, Bürgerbegehren, Normalbürger
Im Wahlprogramm der CDU finden sich dagegen gerade einmal drei Komposita, die mehr Beteiligung der Bürger thematisieren:
volkswirtschaftlich, Volksentscheid, Volksverhetzung, Volksinitiative, Bürgerschaft, Bürgerkrieg, Bürgerinitiative, Bürgerin, Bürgerbusse, Nicht-EU-Bürger, bürgerschaftlich, Bürgertickets, Staatsbürgerschaft, bürgernah, Bürgerbeteiligung, Bürgermeister
Die AfD erklärt damit den Volkswillen für zentral und konstruiert das „Volk“ in Abgrenzung zu Asylsuchenden und Migranten.
Frontstellung gegen das „Establishment“
Die Ablehnung des Establishment hat in der AfD zahlreiche Facetten. Einerseits unterstellt die Partei, Medien, Politik und sonstige Eliten hätten einen Verblendungszusammenhang konstruiert. Die AfD hingegen trete der allgegenwärtige Manipulation mit den Mitteln der Wahrheit und der Vernunft entgegen. Untersucht man, wie häufig Lexeme in den Pressemitteilungen Verwendung finden, die auf Lüge, Manipulation und einen allgegenwärtigen Verblendungszusammenhang verweisen, dann ergibt sich folgendes Bild:
In fast allen Kategorien weist die AfD eine deutlich überdurchschnittliche Referenz auf vermeintliche Manipulationen, Lügen oder verborgene Wahrheiten auf. Bei keiner anderen Partei — außer vielleicht der NPD — ist die Distribution über alle Klassen ähnlich kohärent und verweist somit auf eine Neigung zu Verschwörungstheorien.
Ebenso aufschlussreich ist die Analyse von metasprachlich markierten Ausdrücken. Setzt man Wörter in Anführungszeichen oder distanziert man sich von einer Bezeichnung, indem man ein „sogenannt“ davorsetzt, ist dies ein Indikator für implizite bzw. explizite Sprachkritik. Untersucht man, wie häufig alle Parteien sich solcher metasprachlicher Markierungen bedienen, ergibt sich folgendes Bild:
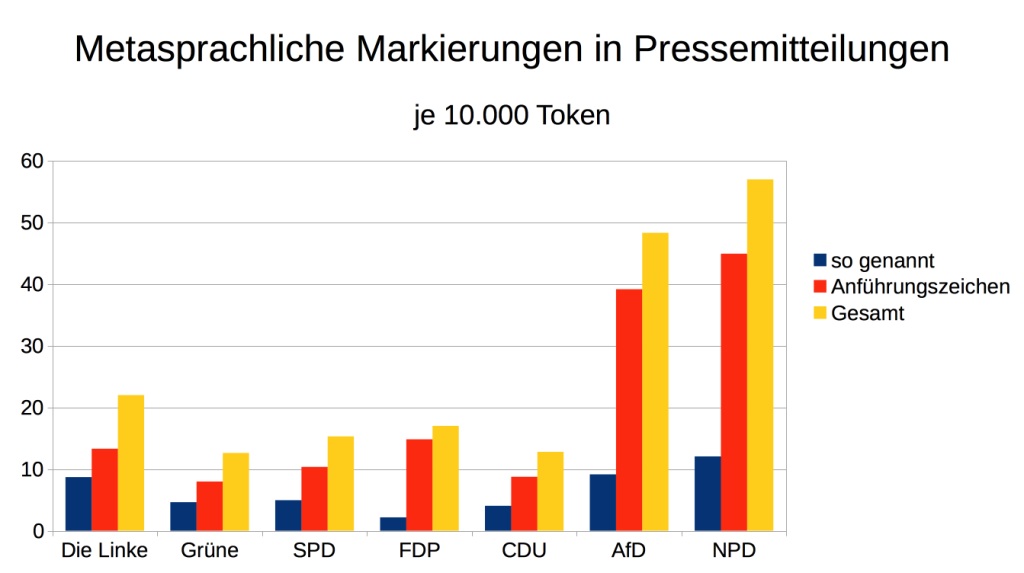
Die AfD bedient sich weitaus häufiger als die anderen Parteien des demokratischen Spektrums metasprachlicher Markierungen und zeigt so ihre Distanz zur herrschenden Semantik. Sie weist eine ähnlich hohe Zahl an metasprachlichen Markierungen wie die NPD auf.
Untersucht man, welche Ausdrücke von der AfD metasprachlich markiert werden, wird die Distanz zum sog. Establishment deutlich. Neben Ausdrücken, die Migration thematisieren, sind dies von der AfD zu bloßer Ideologie verteufelte Wissenschaften sowie Wissenschaftler und sonstige Experten.
| Flüchtlinge und Flüchtlingspolitik | Gender, Diversity | Experten und Akademiker |
|---|---|---|
| Flüchtling | Gender-Mainstreaming | Experte |
| Grenzschutz | Gender Studies | neue Akademiker |
| vorübergehend | soziales Geschlecht | akademisches Prekariat |
| Euro-Islam | geschlechtergerechte Sprache | Wissenschaftler |
| Asyl-Zuwanderung-über-alles | Political Correctness | Rechtsextremismusexperte |
| Völkerwanderung | Gleichstellungsbeauftragte | Elite |
| Parallelgesellschaften | Gender Mainstreaming | Diplom-Sozialwissenschaftler |
Sucht man in den Pressmitteilungen der AfD nach Komposita mit dem lexikalischen Morphem /partei/, so findet man folgende Bezeichnungen für andere Parteien:
Parteienherrschaft, Altpartei, Alt-Partei, Kaderpartei, Blockparteienmanier, Altparteienpolitiker
Die Bezeichnung „Altpartei“ in allen Varianten ist dabei absolut dominant. Dass diese Bezeichnung von Joseph Goebbels und anderen Vertretern der NSDAP gerne benutzt wurde, scheint die AfD nicht weiter zu stören. Als Eigenbezeichnung verwendet die AfD gerne Komposita wie:
Volkspartei, Rechtsstaatspartei, Weckruf-Partei, Konfliktpartei, Mitmachpartei, Anti-Europartei, Oppositionspartei
Die Tatsache, dass die AfD den Rest des Parteiensystems pauschal als überkommene Institution abwertet, zeigt, wie sehr sie sich mit ihrer Rhetorik in traditionelle populistische Anti-Eliten-Diskurse einschreibt.
Zusammenfassung
Die Ergebnisse zur Rhetorik der AfD im Landtagswahlkampf in Rheinland-Pfalz lassen sich wie folgt zusammenfassen:
Die Ergebnisse lassen den Schluss zu, dass der Landesverband der AfD in Rheinland-Pfalz mit einer populistische Kampagne um Wähler wirbt.
Literatur
Kaum ein großes Online-Medium jenseits des Qualitätsjournalismus kommt ohne Horoskop aus. Und das, obwohl schon Adorno der Astrologie vor mehr als 50 Jahren bescheinigte, dass die sozialen und psychologischen Bedingungen, die sie ermöglichten, mit dem (damaligen) allgemeinen Aufklärungszustand unvereinbar seien.
Astrologie zwischen Rationalität und Irrationalität
Aus Sicht der Astrologie wirken Gestirnkonstellationen unmittelbar auf den irdischen Gang der Dinge. Sie vermittelt damit ein Weltbild, in dem jeder Mensch unter dem Einfluss objektiver, abstrakter und depersonalisierter Kräfte handelt. So objektiv mess- und berechenbar der Lauf der Gestirne auch sein mag, über die Art und Weise ihres (vermeintlichen) Einflusses auf die Schicksale der Menschen lässt die Astrologie uns im Dunkeln. Dieses Nebeneinander von Rationalität, Empirismus und Transzendenz hat Adorno im Oxymoron des naturalistischen Supranaturalismus gefasst. Folgt man Adorno, korrespondiert dieses Weltbild der Wahrnehmung vieler Menschen in funktional hochgradig differenzierten Gesellschaften: die Unübersichtlichkeit der Welt und die Sinnlosigkeit und Berdohlichkeit sozialer Prozesse wird durch den Glauben an eine Instanz kompensiert, die ein Versprechen auf rationale Begründbarkeit des ansonsten Unerklärlichen gibt. Auf diese Weise wirkt die Astrologie in doppelter Hinsicht stabilisierend auf die Gesellschaft, indem sie den herrschenden Rationalitätstyp bestätigt und die Irrationalitäten der sozialen Ordnung erklärbar macht.
Das Horoskop ist ein Text. Dieser Text leitet bestimmte Aspekte des Lebens einer Personengruppe, die über den Zeitpunkt ihrer Geburt definiert ist, aus einer aktuellen Gestirnkonstellation kausal ab; das klingt dann etwa so: „Unter dem aktuellen Jupiter-Uranus-Einfluss wird Ihr scharfer Zwillinge-Geist noch einmal geschärft.“ Je ausführlicher ein Horoskop ist, desto gründlicher wird die Gestirnkonstellation als argumentative Ressource genutzt. In den knappen Pressehoroskopen fällt sie dagegen sogar häufig zugunsten deutungsoffener und deshalb für jeden mit individuellem Sinn füllbarer Aussagen weg.
Sprachliche Analysen wie die von Katja Furthmann haben an Pressehoroskopen eine Reihe von Themen (Liebe, Beruf, Freizeit und Freundschaft, Gesundheit, Finanzen) und wiederkehrenden Topoi, die sich um den Metatopos des erfüllten, ausgeglichenen Lebens gruppieren („Sie haben hohe Ansprüche – gut so. Aber bitte verlangen Sie nichts Unmögliches“, „So schön die Sommerpartys auch sind, Sie sollten mal wieder richtig ausschlafen“), herausgearbeitet.
Reverse Engineering des Transzendenten mittels maschineller Textanalyse?
Wenn Horoskoptexte Übersetzungen von Gestirnkonstellationen in für den Einzelnen anschlussfähige Darstellungen künftigen Erlebens sind, dann müsste in der Analyse sprachlicher Muster von Horoskoptexten und ihrer Distribution die höhere Ordnung, die den Gang unserer aller Leben bestimmt, zumindest aufscheinen — so dachte ich. Vielleicht wäre es sogar möglich wie bei einem Reverse Engineering die Strukturen und Verhaltensweisen der Konstruktionselemente unserer Welt zu extrahieren. Ich machte mich also daran, Horoskope zu sammeln.
Das Sammeln der Horoskope gestaltete sich jedoch schwieriger als gedacht. Denn obwohl jedes größere Online-Medium täglich ein Horoskop veröffentlicht, werden die Horoskoptexte nicht archiviert. Meist ist nur das tagesaktuelle Horoskop verfügbar, selten noch das vom Tag vorher und die Horoskope weiterer Tage. Und fast immer stammen die Horoskope aus derselben Quelle, die mit lizensierten Astrologen, Content nach Maß und flexiblen Push- bzw. Pullservices wirbt.
Endlich wurde ich aber in den Tiefen und Oberflächen des Netzes fündig und konnte gemeinsam mit einem Kollegen für den Zweck der Erforschung von Textmustern 383 Tageshoroskope für jedes der zwölf Sternzeichen extrahieren. Eine simple datengeleitete Analyse gängiger Phrasen zeigte schon, dass die insgesamt 4596 Texte hochgradig rekurrent sind. Das ganze Ausmaß der Text-Re-use wurde mir aber erst deutlich, als ich die längste Überschneidung zwischen zwei Texten (longest common substring) berechnete. Mehrere Horoskoptexte waren völlig deckungsgleich. Und nicht nur das.
Im Himmel nichts Neues
Die 4596 Tageshoroskope wurden mit gerade einmal 894 unterschiedlichen Texten bestückt. Von diesen wurden 568 Texte, das sind 65.5%, mehrfach benutzt. 146 von ihnen sogar zehn mal und mehr. Der am häufigsten gebrauchte Text fand 88 mal Verwendung! Der Text besteht aus zwei Sätzen, die den Angehörigen der Zielgruppe am betreffenden Tag eine außerordentliche Selbstreflexion hinsichtlich ihrer Emotionen und Ziele voraussagt und ihnen auch einen erfüllten Kontakt mit ihren Mitmenschen prophezeit:
Sie sind sich Ihrer Gefühle, Wünsche und Bedürfnisse auf ungewöhnlich klare Weise bewusst und können entsprechend für Ihr Wohlbefinden sorgen. Auch für die Anliegen anderer sind Sie offen und begegnen ihnen mit einer menschlichen und warmen Herzlichkeit.
Positive Emotionen und herzliche Kontaktfreude sind durchweg die Themen der am häufigsten verwendeten Tageshoroskope, auch bei dem mit 72 mal am vierthäufigsten verwendeten Text:
Mehr als üblich sprechen Sie über Ihre Gefühle. Durch das Gespräch finden Sie leicht Kontakt und zeigen vermutlich auch Interesse für das Seelenleben anderer. Sie formulieren Ihre Gedanken nicht besonders sachlich und logisch, dafür umso menschlicher.
Der Traum vom Reverse-Engineering platzte endgültig, als ich die Distribution der Text über die Zeit und die Sternzeichen analysierte. Beim häufigsten Horoskoptext lässt diese Verteilung auf den ersten (und auch nicht auf den zweiten) Blick keine Muster erkennen.
Der Text streut unsystematisch über alle Sternzeichen und den gesamten Zeitraum. Einzige Restriktion: Der Text kann am selben Tag nicht bei zwei Sternzeichen gleichzeitig erscheinen. Dagegen ist es aber durchaus möglich, dass er beim gleichen Sternzeichen an zwei aufeinanderfolgenden Tagen erscheint, ja sogar an drei, wie das Beispiel des dritthäufigsten Textes belegt:
Die Analysen über das gesamte Sample zeigten keine nennenswerte Kovariation, der tiefere Sinn der Textwahl blieb ihnen ebenso verborgen wie die für den Uneingeweihten unsichtbaren Kräfte, die unsere Schicksale steuern.
Mein heutiges Horoskop lautet: „Sag es mit einem Lächeln! heißt Ihr Tagesmotto.“ Ich sei heute mitteilsam und kompromissbereit. Meine freundliche, friedfertige Stimmung werde mit mit vielen Menschen in Kontakt bringen und könne zwischen unterschiedlichen Meinungen vermitteln und eine gemeinsame Basis schaffen. Ein guter Tag, um endlich mal wieder zu bloggen, denke ich mir. Und mein heutiger Horoskoptext kommt in meinem Korpus sogar nur neun mal vor! Das ist gemessen an der sonstigen Wiederverwertungsorgie nachgerade ein individueller Text und wird ganz sicher stimmen. Wie alle Horoskope.
Literatur
Adorno, Theodor: Aberglaube aus zweiter Hand. In: Gesammelte Schriften. Band 8. Frankfurt am Main: Suhrkamp 1997, S. 142-167.
Aphek, Edna, Yishai Tobin: The Semiotics of Fortune Telling. Amsterdam u.a.: Benjamins 1989.
Furthmann, Katja: Die Sterne Lügen nicht. Eine linguistische Analyse der Textsorte Pressehoroskop. Göttingen: V&R unipress 2006.
Dieses Jahr organisiere ich die Datenspuren des Chaos Computer Clubs Dresden (C3D2) mit. Sie werden am 24. + 25. Oktober 2015 in den Technische Sammlungen Dresden stattfinden. Im Folgenden der Call for Papers:
Girls and boys,
get up on your feet and make some noise,
because hackers are in the house!
Seit den Enthüllungen von Edward Snowden vergeht kaum ein Tag, an dem nicht Abhör- und Spionageskandale die Newsseiten der Print- und Online-Medien füllen. Diese Skandale schaffen ein neues Bewusstsein dafür, dass als selbstverständlich erachtete Rechte in der schönen neuen digitalen Welt gefährdet sind.
Wo „Jeder ist verdächtig“ das Mantra ist, das aus den vor neugierigen Blicken geschützten Fluren der Sicherheitsapparate bedrohlich nach außen dringt, dort scheint das für Demokratien so notwendige Grundvertrauen zwischen Bürgern und Staat gestört.
Wo die Digitalisierung den gläsernen Menschen schafft und Geheimhaltung ein Privileg des Staates bleiben soll, dort stellt sich die Frage, wie viel Geheimnis eine Demokratie braucht und wie viel sie verträgt.
Wo in immer mehr Lebensbereichen vernetzbare Daten entstehen und das vage Versprechen auf smarte Anwendungen schon genügt, das Beharren auf Datenschutz als obsolet und fortschrittsfeindlich zu diffamieren, dort muss die Frage diskutiert werden, wie viel Datenautonomie wir uns zugestehen wollen und wer diese garantiert.
Die Digitalisierung macht also eine umfassende Neubestimmung des Verhältnisses von Menschen, Staat und Ökonomie erforderlich. Und sie macht es erforderlich, dass die digitalen Avantgarden, die diese Entwicklung in den IT-Abteilungen großer Konzerne, an den Universitäten, in den Hackspaces oder in den Rechenzentren der Nachrichtendienste maßgeblich prägen und mitgestalten, ihre Rolle verstärkt reflektieren.
Der Chaos Computer Club Dresden lädt daher dazu ein, Vorschläge für technische, wissenschaftliche oder künstlerische Beiträge zu den Datenspuren 2015 einzureichen:
Themenfelder
Einreichungsfrist
16. August 2015
Format
Kurzfassung (max. 300 Wörter) für Vortrag, Workshop, Installation/Performance, Junghackertrack
Einreichung
Vorträge und Workshops über das Konferenzsystem „frab“: https://frab.cccv.de/en/DS2015/cfp/session/new
Installationen, Junghackertrack usw. über die Mailingliste: datenspuren@lists.c3d2.de
Kontakt und Rückfragen
Organisationsteam: datenspuren@c3d2.de, Mailingliste: datenspuren@lists.c3d2.de
Benachrichtigung
Eine Benachrichtigung über die Annahme der Beiträge erfolgt bis zum 15. September 2015.
Die Datenspuren sind ein nichtkommerzieller Community-Event. Da wir weder Eintritt noch Teilnahmegebühren erheben ist es uns leider nicht möglich, Honorare zu zahlen. Auch die Bezuschussung von Reise- und Übernachtungskosten ist nur in Ausnahmefällen möglich. Anträge können gerne ans Orga-Team gestellt werden.
See you in da house!
Liebe Freunde der Sicherheit,
in einem früheren Beitrag habe ich argumentiert, dass die „inhaltlichen Suchbegriffe“, die der BND beim „Filtern“ des Internet benutzt, über Topic Models oder ähnliche Verfahren dazu genutzt werden können, Kommunikation thematisch zu analysieren. Das „Filtern“ bei der strategischen Fernmeldeüberwachung wäre dann faktisch eine Analyse, für die das Bundesverfassungsgericht hohe Hürden gesetzt hat. Heute möchte ich zeigen, wie die Kombination von Topic Models und Metadaten dazu eingesetzt werden kann, thematische Profile von politischen Szenen zu berechnen.
Was sind Topic Models?
Topic Models sind Algorithmen zur Aufdeckung thematischer Strukturen in Texten. Sie gewichten und messen die Affinität von Inhaltswörtern in Textexemplaren eines Korpus. Häufig miteinander auftretende Wörter, die eine hohe Themenspezifizität aufweisen, werden als „Topics“ interpretiert. Diese Lexemcluster haben keine Namen; ihre Benennung ist ein Akt der Interpretation. Ebenso erfolgt die Ermittlung der Anzahl der Topics in den Standardverfahren nicht datengeleitet, sondern in Abhängigkeit von Festlegungen des Forschers.
Meinungsbilder aus dem Internet
Das Innenministerium ließ verlauten: „Wir brauchen eine belastbare Erfassung von Meinungs- und Stimmungslagen der Bevölkerung. Es liegt kein Eingriff in das allgemeine Persönlichkeitsrecht vor, wenn eine staatliche Stelle im Internet verfügbare Kommunikationsinhalte erhebt, die sich an jedermann oder zumindest an einen nicht weiter eingrenzbaren Personenkreis richten.“ Die Folge: alle Nachrichtendienste investieren in die open source intelligence.
Über welche Themen diskutieren linke Szenen?
Will man beispielsweise wissen, womit sich linke Szenen im deutschsprachigen Raum beschäftigen, kann man eine linke News-Site wie http://linkunten.indymedia.org auf ihre Topics hin analysieren. Auf der Subdomain von indymedia.org werden nach Meinungsverschiedenheiten in der Redaktion von Indymedia Deutschland und dem Bedürfnis nach einer engeren Verntezung süddeutscher Szenen Nachrichten veröffentlicht. Das Portal ist inzwischen aktiver als das deutschsprachige indymedia.org. Auch wenn grundsätzlich Nachrichten aus allen Regionen veröffentlicht werden, liegt ein spezieller Fokus auf dem südwestdeutschen Raum. Wendet man auf sämtliche dort publizierten Texten Topic Modelling an, ordnet sich der Wortschatz aufgrund seiner Distribution in folgende Gruppen, für die relativ leicht Namen gefunden werden können:
Themenschwerpunkte linker Szenen
Weil die Artikel auf http://linkunten.indymedia.org unter anderem nach Regionen verschlagwortet sind, ist es möglich, für einzelne linke Szenen Topic-Profile zu erstellen und die Intensität der Aktivitäten zu berechnen. Die unten stehende Grafik zeigt das Topic-Profil der Dresdner Szenen im Vergleich zu anderen Szenen in Deutschland. Sie zeigt die Differenz zum Durchschnitt der normalisierten relativen Auftretenshäufigkeiten der jeweiligen Topics im Gesamtkorpus.
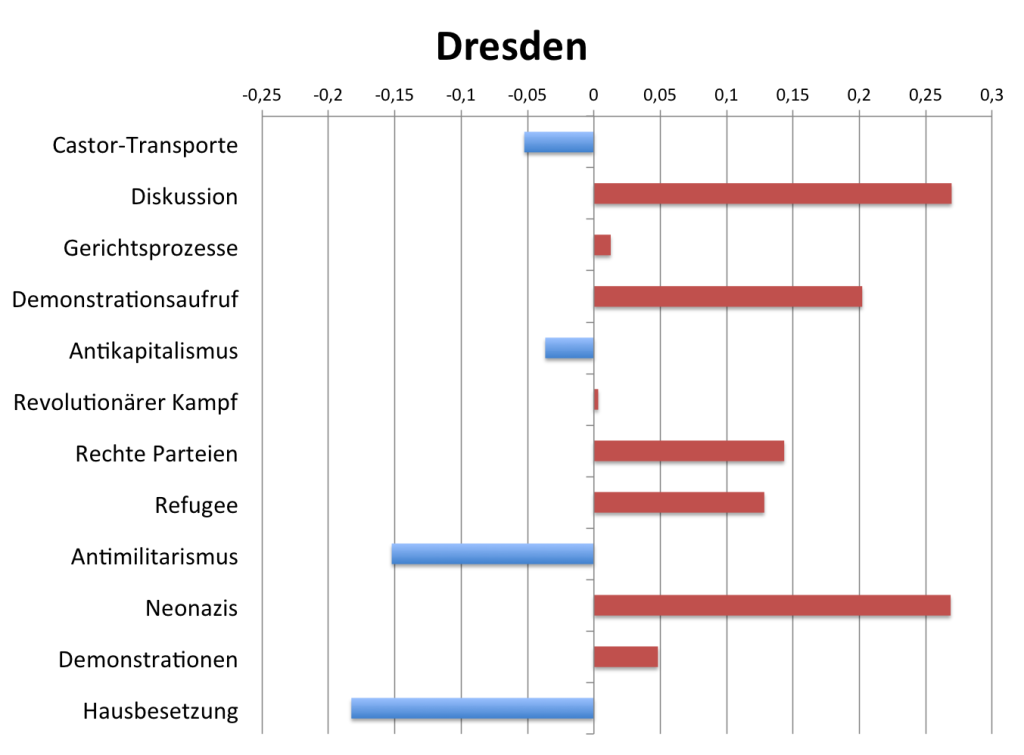
In Dresden wird demnach überdurchschnittlich häufig über Neonazis, rechte Parteien und Flüchtlinge berichtet, zu Demonstrationen aufgerufen und über Diskussionen in und außerhalb der Szene berichtet. Antimilitarismus und Hausbesetzungen spielen hingegen eine vergleichsweise geringe Rolle.
Interessiert man sich für einen Vergleich von Szenenprofilen, kann man die Themendistributionen in Spinnengrafiken übereinanderlegen, wie im folgenden Beispiel für Wien und Salzburg:
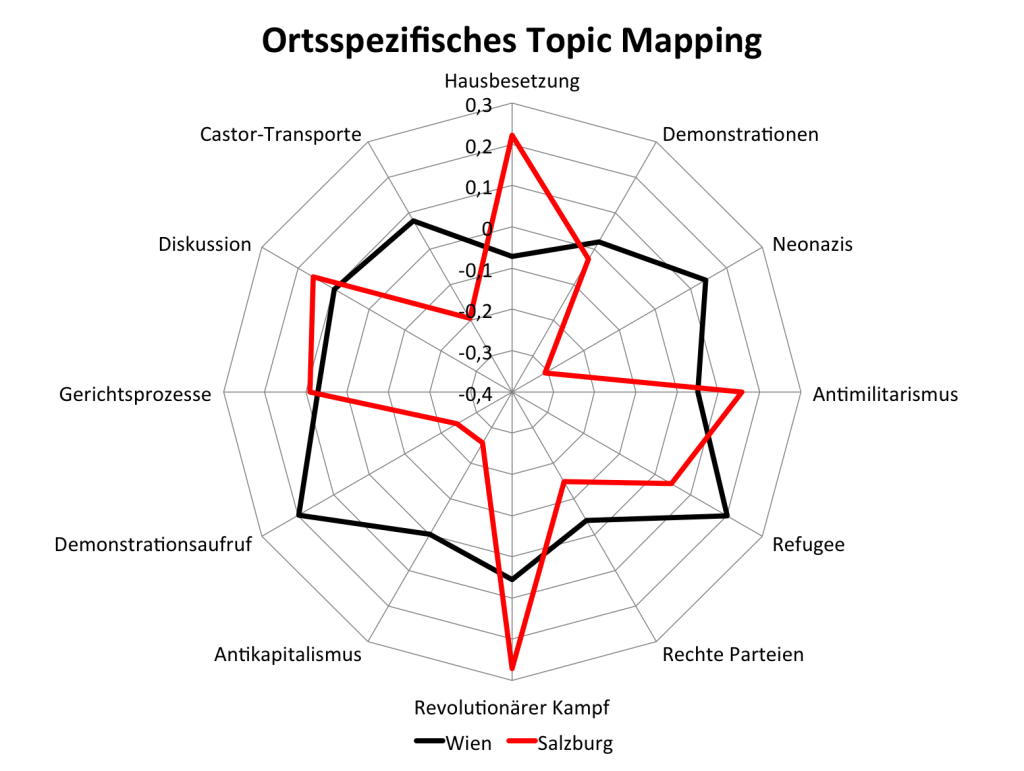
Ebenso ist es möglich, die Affinität einzelner Szenen zu relevanten Topics zu analysieren. Von besonderem Interesse für Sicherheitsbehörden könnte ja beispielsweise das Topic „Revolutionärer Kampf“ sein. Eine Analyse der ortsspezifischen Frequenz dieses Topics im Korpus ergibt folgendes Städteranking:
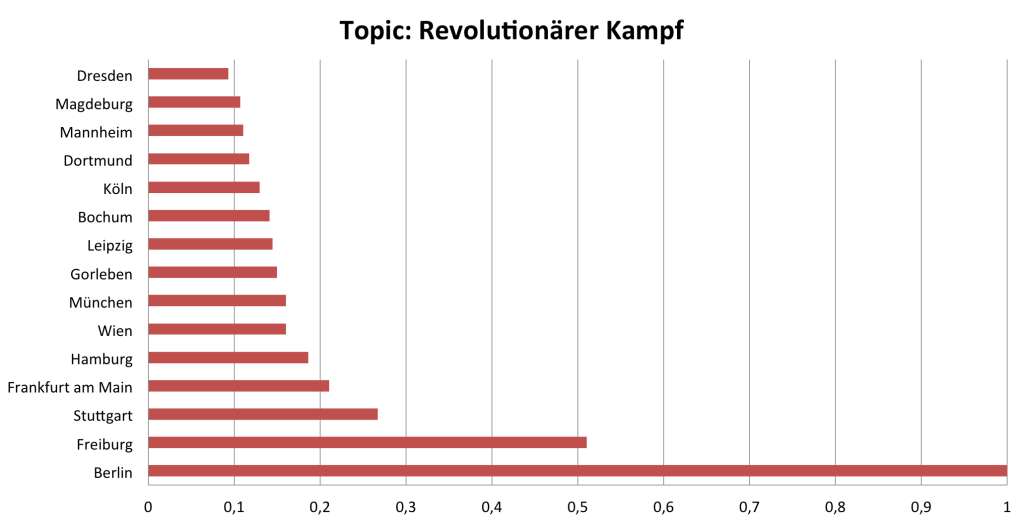
Topic Models sind ein eleganter Weg, um sich mit relativ einfachen Mitteln einen Überblick über die inhaltlichen Prägungen von Korpora zu verschaffen. Maßnahmen gegen Topic Models laufen ins Leere, außer man ist bereit, auf inhaltlich kohärente Diskussionen zu verzichten.
Der 31c3 war großartig! Danke an alle, die zu seinem Gelingen beigetragen haben! arche3000 und ich haben auf einen Vortrag mit dem Titel „Mein Bot der Kombattant: Operative Kommunikation im digitalen Informationskrieg“ gehalten. In dem Vortrag haben wir uns mit der Frage beschäftigt, wie sich der Informationskrieg in digitalen Medien, speziell in sozialen Medien wandelt und welche demokratietheoretischen und informationsethischen Fragen sich daraus ergeben. Eine Aufzeichnung des Vortrags findet sich hier:


