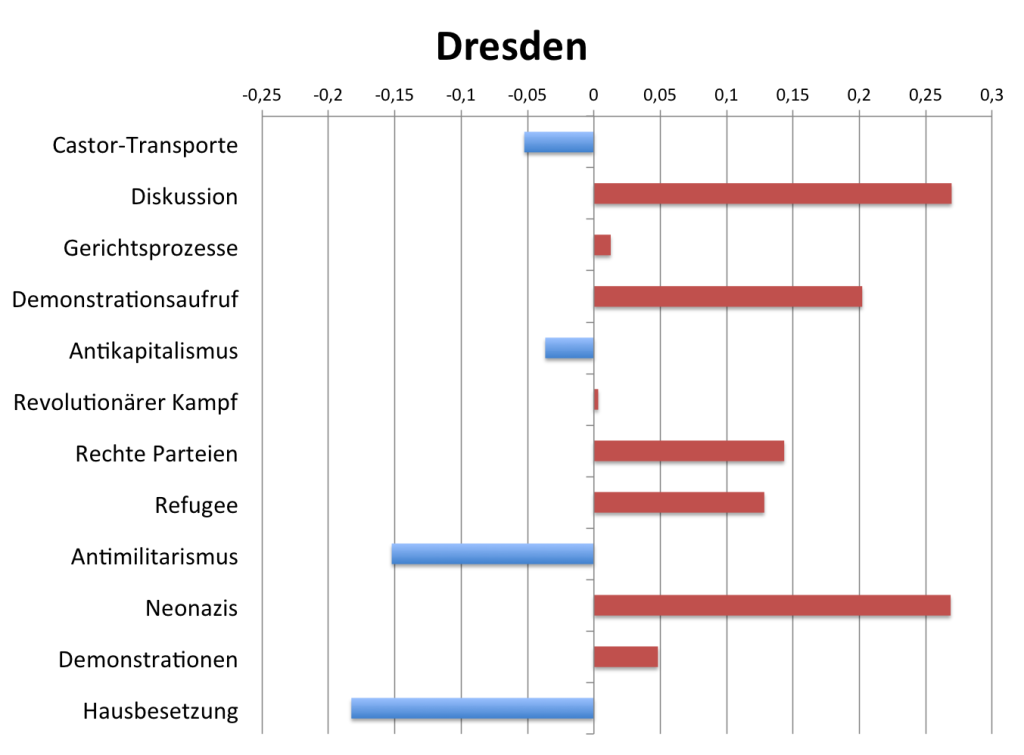
Liebe Freunde der Sicherheit,
Die Verfahren, die bei der maschinellen Autorenidentifizierung zum Einsatz kommen, wurden im Verlauf der Geschichte immer mächtiger, analog zur Entwicklung der Rechenleistung von Computern. Die computergestützte Autorenerkennung kann grob in drei Phasen eingeteilt werden.
1. Die Suche nach globalen Konstanten
Ausgehend von der Annahme, dass dem Stil eines Autors etwas Invariantes eignen müsse, waren die ersten Versuche, Autorschaft aufgrund sprachlicher Merkmale zuzuschreiben, von der Suche nach einem Maß geprägt, das die stilistische Einmaligkeit in einem einzigen Wert ausdrückt. Ich habe an anderer Stelle (hier und hier) einige Werte zur Wortschatzkomplexität vorgestellt und getestet, die in der Forschung als Repräsentanten von Ideolekten verstanden wurden.
2. Autorenidentifizierung mittels multivariater Statistik
Während die Klassifikation mittels einer autorspezifischen Konstanten ein univariates Verfahren ist, wurde ab den 1960er Jahren damit begonnen, mehrere Merkmale von Texten zur Identifizierung von Autorschaft heranzuziehen. Das grundlegende Verfahren dabei ist, einzelne Dokumente als Punkte in einem mehrdimensionalen Raum aufzufassen. Der wahrscheinliche Autor eines in Frage stehenden Textes ist dann jener, dessen Texte die größte Nähe zum Punkt des anonymen Textes im multidimensionalen Raum haben.
3. Klassifikation mittels maschinellen Lernens
Bei der Autorenidentifikation wird seit den 1990er Jahren mit überwachtem maschinellen Lernen gearbeitet. Ziel des maschinellen Lernens ist es, einen Klassifikator zu finden, der ein Set an Texten möglichst gut in Klassen einteilt, um danach zu prüfen, welcher Klasse der Klassifikator den anonymen Text zuordnen würde. Hierfür werden Merkmale von Trainingstexten, also von Texten, von denen die Autoren bekannt sind, als numerische Vektoren abgebildet. Mit Methoden maschinellen Lernens sucht man dann im Vektorraum nach Klassengrenzen, die eine Klassifikation mit möglichst wenigen Fehlern ermöglicht.
Im Folgenden möchte ich die verschiedenen Verfahren anhand diverser linguistischer Merkmale illustrieren, vor allem mit dem Ziel, einen kritischen Blick darauf zu ermöglichen, was eigentlich gemessen wird, wenn Autorenidentifikation betrieben wird. Zur Illustration wähle ich einen fünf Jahre zurückliegenden Fall, bei dem das BKA linguistisches Profiling betrieb.
Der „Fall“
Am 31. Juli 2007 brannten in Brandenburg / Havel mehrere Fahrzeuge der Bundeswehr. Drei mutmaßliche Täter wurden bei der Ausführung des Brandanschlags verhaftet. Am 1. August 2007 stürmte ein Sondereinsatzkommando auch die Wohnung des Soziologen Andrej Holm. Ihm wird vorgeworfen, Mitglied der „militanten gruppe“, einer damals als terroristisch eingestuften linksradikalen Gruppierung zu sein, die auch für die Brandanschläge in Brandenburg verantwortlich war. Die Polizei hielt ihn für den intellektuellen Kopf der Gruppe und den Verfasser der zahlreichen Bekennerschreiben und Diskussionspapiere, die die militante Gruppe veröffentlicht hatte. Die militante gruppe wird für 25 Brandanschläge, vornehmlich auf Fahrzeuge von Polizei und Bundeswehr, aber auch auf Sozial- und Arbeitsämter in den Jahren 2001-2007 verantwortlich gemacht. Sie gab 2009 ihre Selbstauflösung bekannt. Sie wird nicht mehr als terroristische, sondern als linksradikale kriminelle Vereinigung angesehen.
Andrej Holm hatte sich in den Augen der Polizei dadurch verdächtig gemacht, dass seine wissenschaftlichen Arbeiten in sprachlicher Hinsicht Ähnlichkeiten mit den Bekennerschreiben der Gruppe hatten: die Polizei stellte fest, dass Lemmata wie „Gentrifizierung“ und „Prekarisierung“ in den Texten Holms und der mg signifikant häufig vorkamen. Die Polizei hatte gegooglet, berichteten die Medien. Immerhin auch ein computergestütztes Verfahren. Da Verfassungsschutzbehörden sicherlich auch in den Fall involviert waren, kann jedoch auch gemutmaßt werden, dass andere, evtl. auch komplexere Verfahren der maschinellen Autorenidentifizierung zum Einsatz kamen, auch wenn diese im Ermittlungsverfahren gegen Andrej Holm keine weitere Rolle spielen konnten.
Die „Verdächtigen“
Aus Sicht der forensischen Linguistik soll nun der Fall neu aufgerollt werden. Um es gleich zu Beginn zu sagen: Das hier ist kein ernst zu nehmendes linguistisch-forensisches Gutachten und die Ergebnisse sind in keiner Weise dazu geeignet, Verdächtige zu überführen. Das zeigt auch schon die Liste jener, die ich „verdächtige“, Autoren der mg-Texte zu sein, die mithin mit Texten in meinen Trainingsdaten vertreten sind.
Zunächst folge ich unseren Strafverfolgungsbehörden und nehme zwei Korpora des vom BKA Verdächtigten Andrej Holm:
- gentrification blog, Blog von Andrej Holm: 491 Posts, 304.406 laufende Wortformen, 2008-2012
- gentrification Theorie, wissenschaftliche Aufsätze von Andrej Holm: 5 Aufsätze, 40.853 laufende Wortformen, 2004-2012.
Wenn Terrorverdacht im Raum steht, dürfen natürlich auch Ermittlungen in islamistischen Kreisen nicht fehlen:
- Ich nehme zwei Korpora mit allen Forenbeiträgen der Autoren aus einem salafistischen Forum (derW****, 570.016 / Muu****, 268.165), die sich irgendwann einmal zur Situation auf dem Wohnungsmarkt geäußert haben, und
- das Blog der Islambruderschaft Deutschland, 129.965 laufende Wortformen
Auch muss man aufpassen, sich nicht dem Vorwurf auszusetzen, auf dem rechten Auge blind zu sein:
- Ich nehme zwei Autorenkorpora aus dem inzwischen geschlossenen NPD-Forum Gernot (88.161), Spinne (147.144) und
- Michael Kühnens „Schriften“, 111.873 laufende Wortformen.
Zudem will ich überprüfen, ob nicht Alt-RAFler oder andere ehemalige Linksterroristen als militante Gruppe wieder aktiv sind. Daher nehme ich:
- die Texte der Revolutionären Zellen (203.492) und
- die Texte der Roten Armee Fraktion (195.939).
Ich nehme auch noch zwei Diskutanden aus dem Diskussionsforum eines globalisierungskritischen Netzwerks hinzu, weil Globalisierungskritiker nunmal verdächtig sind:
- bur*** (102.955 laufende Wortformen), Pom*** (21.241 laufende Wortformen), 2007-2009.
Hinzu kommen noch zwei Autoren, die sich durch ihre publizistisches Wirken verdächtig gemacht haben:
- Fefe, wegen Verbreitung von Verschwörungstheorien in seinem Blog: 24.239 Posts, 1.928.027 laufende Wortformen, 2005-2012
- Franz Josef Wagner mit seiner Kolumne „Post von Wagner“, die von manchem als schwer staatsgefährdend empfunden wird: 1.390 „Briefe“, 233.008 laufende Wortformen, 2006-2012.
Später kommen dann noch die Texte der militanten gruppe dazu:
- 15 Anschlagserklärungen (27.828)
- 4 mg express (7.679)
- 14 Texte zur Militanzdebatte (50.078)
- 8 thematische Beiträge (90.328)
Die Suche nach globalen Konstanten ist so wenig zeitgemäß, dass ich hier auf die älteren Blogbeiträge verweise. Weil sich die Ergebnisse so gut veranschaulichen lassen, illustriere ich das Vorgehen bei der Autorenidentifizierung mittels multivariater Statistik anhand der Clusteranalyse.
Textclustering
Die Clusteranalyse ist ein strukturentdeckendes Verfahren der multivariaten Statistik. Sie entdeckt Gruppen von „ähnlichen“ Objekten. In unserem Fall sind die Objekte Texte, die aufgrund ihrer Ähnlichkeit bzw. Unähnlichkeit im Hinblick auf linguistische Merkmale gruppiert werden. Natürlich ist es von entscheidender Bedeutung, anhand welcher linguistischer Merkmale ich die Gruppierung vornehmen. Die folgenden drei Analysen zeigen eindrucksvoll, wie unterschiedlich die Ergebnisse bei je unterschiedlichen linguistischen Kategorien sind. Der Übersichtlichkeit halber habe ich mit den Gesamtkorpora gerechnet.
Sicherheitsinformatiker halten Funktionswörter für besonders gute linguistische Kategorien, weil sie glauben, dass sie unbewusst verwendet werden und daher auch nicht manipuliert werden können. Führt man eine Clusteranalyse anhand der Distribution von Funktionswörtern (z.B. Artikel, Präpositionen, Konjunktionen) durch, dann erhält man folgendes, eher unklare Bild:

Dendrogramm Funktionswörter
Die Texte Andrej Holms und der militanten Gruppe sind jeweils gelb gekennzeichnet, jedoch durch verschiedene Schriftfarben von einander abgesetzt. Eine Autorschaft Andrej Holms kann auf der Basis dieser Daten nicht abgeleitet werden — im Gegenteil. Zusammen mit anderen eher weltanschaulich-theorielastigen Texten (RZ, RAF, Islambruderschaft, Kühnen) bilden die Textkorpora der militanten Gruppe ein eigenes Cluster. Offenbar fungiert hier die Textsorte als Hintergrundvariable. Dass Fefe sich in der Nachbarschaft von Franz Josef Wagner befindet, ist ein interessantes Detail.
Führt man eine Clusteranalyse anhand der Distribution von Inhaltswörtern durch, kommt man zu einer anderen Gruppierung der Texte.

Dendrogramm Inhaltswörter
Die Texte zur Rechtfertigung linker Gewalt (RAF, RZ, mg) bilden ein Cluster. Auch Andrej Holms wissenschaftliche Texte und Blogbeiträge lassen sich zusammen als eigene Gruppe interpretieren, die aber einen großen Abstand zum Cluster der mg-Texte aufweist. Obwohl also bestimmte Inhaltswörter das BKA dazu verleitet haben, Andrej Holm zu verdächtigen, ergibt die Analyse von Inhaltswörtern, dass auf ihrer Basis eine Autorschaft kaum wahrscheinlich ist. Ansonsten zeigt das Dendrogramm, das Inhaltswörter sich nur leidlich gut für die Identifizierung inhaltlicher Gemeinsamkeiten eignen. Zwar liegen die Texte von Islambruderschaft und Salafisten in einem Cluster, allerdings befindet sich dort auch Franz Josef Wagner. Auch irritiert die Nachbarschaft, in der sich Fefe befindet.
Ein weitere Kategorie, mittels derer man Texte in interessanter Weise gruppieren kann, sind komplexe n-Gramme; vgl. hierzu einen älteren Beitrag.

Dendrogramm komplexe n-Gramme
Die Ananlyse zeigt hier zwar, dass die Texte Andrej Holms zusammen mit den Texten der militanten Gruppe ein Cluster bilden, allerdings ist auch hier offensichtlich, dass Texte, die entweder wissenschaftlich argumentieren oder sich stilistisch den Anschein von Wissenschaftlichkeit (Kühnen, RAF, RZ) geben wollen, gemeinsam gruppiert wurden. Es ist damit relativ offensichtlich, dass wir hier nicht Autorschaft messen, sondern Stilkonventionen oder Textsorten.
Maschinelles Lernen
Beim maschinellen Lernen sind die oben beschriebenen Korpora die Trainingsdaten, mit deren Hilfe ein Klassifikator berechnet wird. Der Klassifikator kann dann dazu benutzt werden, die anonymen Texte einer Klasse zuzuweisen. Bei der Autorenidentifizierung mittles maschinellem Lernen benutzt man üblicherweise eine große Vielzahl an linguistischen Merkmalen. Ich habe mich auf folgende beschränkt:
- relative Frequenz intensivierende Partikel (Gradpartikel)
- durchschnittliche Satzlänge
- Wortschatzkomplexitätsmaß Yule‘s K
- relative Frequenz Passiv-Konstruktionen
- relative Frequenz Konjunktiv I
- relative Frequenz Konjunktiv II
- relative Frequenz von Partizipialkonstruktionen
- relative Frequenz von Präpositionalgruppenclustern
- Schwierigkeit der Präpositionalgruppencluster (durchschnittliche Häufigkeitsklasse (Quelle: DeReKo) der in Präpositionalgruppenclustern auftretenden Präpositionen)
Anders als bei den Untersuchungen vorher wurde nicht mit Gesamtkorpora gerechnet. Zum Trainieren des Klassifikators wurden alle Einzeltexte benutzt, die mindestens 800 laufende Wortformen haben.
Um zu illustrieren, wie so ein Klassifikator aussehen kann, habe ich das Entscheidungsbaumverfahren benutzt. Beim Entscheidungsbaumverfahren wird eine Datensatz Schritt für Schritt in Unterklassen geteilt.

Aus den Trainingsdaten abgeleiteter Entscheidungsbaum
Im obigen Graph kodiert jeder Pfad vom Wurzelknoten zu einem Blatt eine Entscheidungsregel. Berechnet man nun die linguistischen Merkmale der anonymen Texte, in unserem Fall der Texte der militanten Gruppe, dann können diese mit Hilfe der Entscheidungsregeln einem Autor zugewiesen werden.
Von den 41 Texten der militanten Gruppe werden mittels dieses Klassifikators 13 den Revolutionären Zellen zugeschrieben, 4 einem Diskutanden aus einem Forum, einen Beitrag zur Militanzdebatte soll Fefe verfasst haben, und 23 Texte der militanten Gruppe werden als den Blogbeiträgen von Andrej Holm am ähnlichsten klassifiziert. Dabei ist es bei den allermeisten Blogbeiträgen nur eine Kombination zweier Merkmale, die für die Klassifikation als Holm-Text verantwortlich sind: eine geringe Anzahl von Konjunktiv-II-Formen und ein relativ hoher Anteil Partizipialkonstruktionen. Ich habe die betreffende Entscheidungsregel in der folgenden Abbildung farblich markiert.

Entscheidungsbaum mit markierter Entscheidungsregel
Der Konjunktiv II ist eine grammatische Form, die häufig zum Ausdruck von Höflichkeit benutzt wird oder der Formulierung von Irrealem (etwa in irrealen Konditionalsätzen) dient. Es ist daher nicht falsch anzunehmen, dass es Zusammenhänge zwischen dem Inhalt des Gesagten und der Frequenz von Konjunktiv-II-Formen gibt. Partizipialkonstruktionen sind hingegen typische Merkmale eines Nominalstils, die in einem Wissenschaftler-Blog durchaus erwartbar sind, auch in meinem.
Messen wir hier also tatsächlich einen Individualstil? Oder nicht doch eher inhaltliche und kommunikationsbereichsspezifische Merkmale? Und wenn wir nicht genau wissen, ob unsere Messinstrumente valide sind, wie verhält es sich dann eigentlich mit der prognostischen Güte unseres Modells? Die Frage ist natürlich eine rhetorische, denn wenn die Merkmale nicht valide sind, dann ist der Klassifikator zwar gut genug, um die Trainingsdaten zu klassifizieren, aber er hat keinerlei prognostischen Wert.
Die Analyse zeigt, wie sehr die maschinelle Autorenidentifikation davon abhängig ist, anhand welcher linguistischer Merkmale wir die Klassifikation vornehmen und ob diese Merkmale tatsächlich als Repräsentanten eines Individualstils gelten können. Die Bedeutung kommunikationsbereichs-, textsortenspezifischer und inhaltlicher Faktoren ist bislang von der Forschung noch nicht annähernd hinreichend gewürdigt. Die Gefahr fälschlicherweise in Verdacht zu geraten, ist daher groß.