Friederike Werner von ZEIT Online hat mich eingeladen, ein Wissensquiz zur Wortwahl, insbesondere zur Sprache der Herabsetzung und Ausgrenzung auszudenken.
Die korrekten Antworten und Erläuterungen habe ich auf hassrede.de zusammengestellt.
Computer- und korpuslinguistische Methoden des politisch motivierten Internet-Monitorings
Friederike Werner von ZEIT Online hat mich eingeladen, ein Wissensquiz zur Wortwahl, insbesondere zur Sprache der Herabsetzung und Ausgrenzung auszudenken.
Die korrekten Antworten und Erläuterungen habe ich auf hassrede.de zusammengestellt.
Hate Speech ist in aller Munde, und das in doppelter Hinsicht: Einerseits flutet ein Tsunami an Hasskommentaren das Internet und untergräbt in den Augen vieler die Fundamente der demokratischen Meinungsbildung. Andererseits erleben wir, wie Hate Speech auch im öffentlichen Diskurs zu einer eigenständigen Kategorie der verbalen Herabsetzung wird. Ein Indiz dafür ist der Anstieg des Gebrauchs einschlägiger Lexeme in SPIEGEL Online in den letzten zwei Jahren (bis 8/2016). Neben dem Ausdruck der „Volksverhetzung“, der einen Straftatbestand bezeichnet, ist die Anzahl der Nutzung der Ausdrücke „Hetze“, „Hetzer“ und „hetzerisch“ sowie von „Hassbotschaft“ und „Hasskommentar“ im Ressort Innenpolitik deutlich gestiegen:

Auffällig ist freilich, dass das Wort „Hetze“ häufiger verwendet wird als das Englische „Hate Speech“ und seine Lehnübersetzung „Hassrede“. Im Ressort Netzwelt freilich haben Komposita mit dem lexikalischen Morphem /hass/ wie „Hassbotschaft“, „Hasskommentar“ oder „Hassposting“ den Ausdruck „Hetze“ im Jahr 2016 noch überholt. Und auch die Bezeichnungen „Hate Speech“ und „Hassrede“ kommen deutlich häufiger vor, als in den Jahren vor 2015.

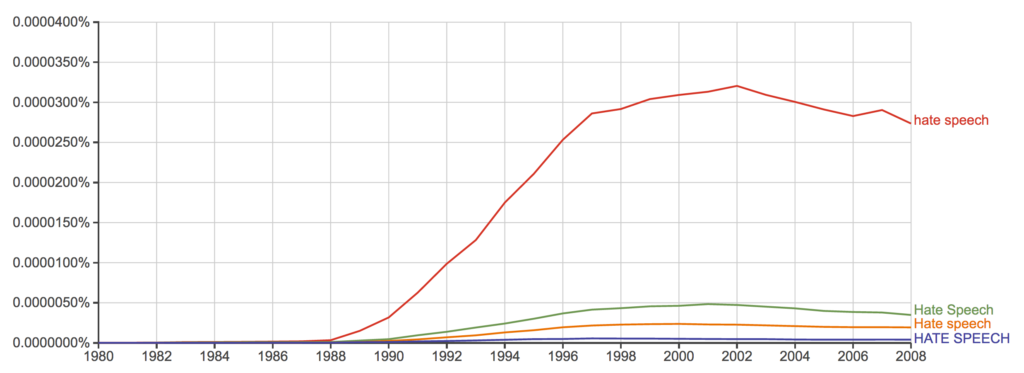
Die Analyse zeigt, dass der Ausdruck „Hate Speech“ und seine Lehnübersetzung „Hassrede“ sowie davon semantisch inspirierte Komposita wie „Hassbotschaft“ – und mit ihnen Hassrede als spezifische Form verbaler Herabsetzung – im Kontext von Netzdiskursen geprägt wird. Im Englischen, in dem sich die Bedeutung von „Hate Speech“ auch aus der semantischen Nähe zu „Hate Crime“ (einem Delikt gegen ein nach dem Kriterium der vermeintlichen Zugehörigkeit zu einer gesellschaftlichen Gruppe ausgewählten Opfer) speist, ist der Ausdruck schon länger eingeführt, wie ein Blick auf die Daten im Google n-Gram-Viewer belegen.
Trotz aller Kritik am Begriff der Hassrede und trotz der heftigen Diskussionen darüber, wie mit Hate Speech in sozialen Medien zu verfahren sei, hat es den Anschein, dass es den Kritiken (noch) nicht gelungen ist, den Begriff negativ im Sinn einer undemokratischen Redeverbotsideologie zu besetzen, wie dies beim Ausdruck „politische Korrektheit“ der Fall ist.
So spielt zwar auch in den Online-Publikationen des berüchtigten Kopp Verlag (hier ausgewertet: info.kopp-verlag.de) die Beschäftigung mit dem Thema eine immer größere Rolle. Dennoch wird hier dominant von „Hetze“ gesprochen, als „Hate Speech“ oder „Hassrede“ wird das Thema erst seit 2016 geframet.

Auch wenn der Satz „Truth – The New Hate Speech“ also in Deutschland (noch) nicht sinnvoll sagbar ist, zeigen die von den Wortfamilien der Morpheme /hetze/ und /hass/ bezeichneten Sachverhalte bei SPIEGEL Online und im Kopp Verlag nur geringe Schnittmengen, was auf eine lagerspezifische strategische Instrumentalisierung der Begriffe hindeutet.
Der folgende Graph zeigt Komposita mit dem lexikalischen Morphem /hass/ in den Korpora von info.kopp-verlag.de und SPIEGEL Online 2015 und 2016. Rot markiert sind Komposita, die sich ausschließlich beim Kopp Verlag fanden. Grau sind Komposita, die nur im Korpus von SPIEGEL Online vorkommen. Schwarz dargestellte Komposita finden sich in beiden Korpora.

Während der Kopp-Verlag vom „Leser-Hass“ und „Deutschland-Hass“ schreibt und damit auf patriotische „Mainstream-Presse“-Verächter zielt, thematisiert SPIEGEL Online den Medienhass, also den Hass auf die Medien. Entsprechend werden viele Determintativkomposita mit /hass/ als Erstglied in Kontexten verwendet, in denen über die Bestrebung zur Ächtung von Hate Speech als staatliche Propaganda- und Zensurmaßnahme berichtet wird; oder sie bezeichnen Sachverhalte, die mit dem muslimischen Glauben im Zusammenhang stehen („Hass-Moschee“).
Die gleiche Tendenz ist bei Komposita mit dem lexikalischen Morphem /hetze/ beobachtbar. Hier wird beim Kopp-Verlag die Selbstviktimisierung der Neuen Rechten („AfD-Hetz“, „Medienhetze“) und die Freundschaft zu Russland („Kriegshetze“ westlicher Politiker) sichtbar, aber auch die vermeintliche „Hetzjagd“ auf Kritiker der Flüchtlingspolitik und der „Hetz-Pranger“ der BILD, die Emittenten von Hate Speech in sozialen Netzwerken mit Klarnamen und Foto abgebildet hatte, verweisen darauf, dass man sich selbst und die eigenen Sympathisanten als Opfer eine „Hetzkampagne“ sieht. Bei SPIEGEL Online dominiert dagegen eine Mischung aus Internet- und Flüchtlingsthematik, wenn von „Hetze“ die Rede ist.

In der gegenwärtigen Konjunktur von Wort und Sachverhalt ist der Begriff der Hate Speech umkämpft. Während die begriffliche Unschärfe im Deutschen jede Art der gruppenbezogenen Beleidigung als Hate Speech deutbar macht und so die Extension des Begriffs auf viele Phänomene ausweitet, die im wissenschaftlichen Diskurs nicht als Hate Speech gelten würden, wird von anderer Seite versucht, den Begriff umzudeuten in ein Instrument der Unterdrückung freier Meinungsäußerung und Zensur. Ob dies gelingt dürfte wesentlich auch davon abhängen, ob es gelingt, im öffentlichen Diskurs eine verständliche und handhabbare Bedeutung von „Hate Speech“ zu konturieren, die nicht leicht als Ressource zum Ausschluss missliebiger Positionen missbraucht werden kann, sondern Formen sprachlicher Herabwürdigung benennt und ächtet, die gruppenbezogen sind und deren herabwürdigende Kraft sich aus als unveränderlich gedachten Zuschreibungen an die Vertreterinnen und Vertreter dieser Gruppe speist.
(Erstmals publiziert auf hassrede.de)
Liebe Freunde der Sicherheit,
Experten begegnen uns in vielerlei Gestalt in allen Gazetten und auf allen Kanälen. Vom Finanzexperten, der uns treffsicher Auswege aus Finanzkrise weist, über den Sicherheitsexperten, der zuverlässig bei jeder Gelegenheit die Vorratsdatenspeicherung fordert, bis hin zum Spezialexperten in Fefes Blog, der als Kompetenzbombe in jedem Wissensbereich einen Volltreffer landet.
Der Experte ist ein sprachliches Konstrukt, der schon durch den bloßen Akt der Zuschreibung von Expertentum zu dem wird, als der er in den Medien erscheint: zum Experten. Dabei ist das Wort „Experte“ äußerst produktiv. Mit ihm lassen sich Unmengen an Komposita, Wörter wie „US-Hinrichtungsexperte“, „Bundesbahn-Technikexperte“, „SPD-Spielbanken-Experte“, „Humorexperte“, „American-Express-Tarifexperte“ oder Klassiker wie „Allround-Experten“, bilden. Die Journalisten von Spiegel-Print beispielsweise haben seit 1947 rund 6000 unterschiedliche Experten-Typen gekürt.
Der Siegeszug des Experten
Aber seit wann gibt es den Typus des „Experten“ eigentlich in den Medien? Vergleicht man die Frequenzentwicklung des Wortes „Experte“ im gedruckten Spiegel mit der von Bezeichnungen für in akademischen Kontexten tätigen Personen wie „Wissenschaftler / Wissenschaftlerin“, „Forscher / Forscherin“ und „Professor / Professorin“, dann wird offensichtlich, dass die 68er auch am Siegeszug des Expertentums Schuld sind:

Entwicklung der relativen Frequenz der Wörter „Forscher“, „Experte“,
Wissenschaftler“ und „Professor“ und Komposita je 100.000 Wörter im SPIEGEL (print)
Nach 1968 steigt der Gebrauch des Wortes „Experte / Expertin“ und seiner Komposita sprunghaft an und verharrt dann relativ konstant auf hohem Niveau. Gleichzeitig geht der Gebrauch der Bezeichnung „Professorin / Professor“ im SPIEGEL nach 1968 dramatisch zurück, auch im Verhältnis zur Zeit vor der sogenannten Studentenrevolte, die natürlich ausführlich im SPIEGEL verhandelt wurde. Ein Trend übrigens, der sich bis in die Gegenwart fortsetzt. Die Grafik zeigt auch, dass seit den 1980er Jahren die Bezeichnung „Forscher / Forscherin“ im journalistischen Trend liegt. So produktiv im Hinblick auf die Wortbildung wie das Wort „Experte“ ist aber keines der anderen Lemmata:
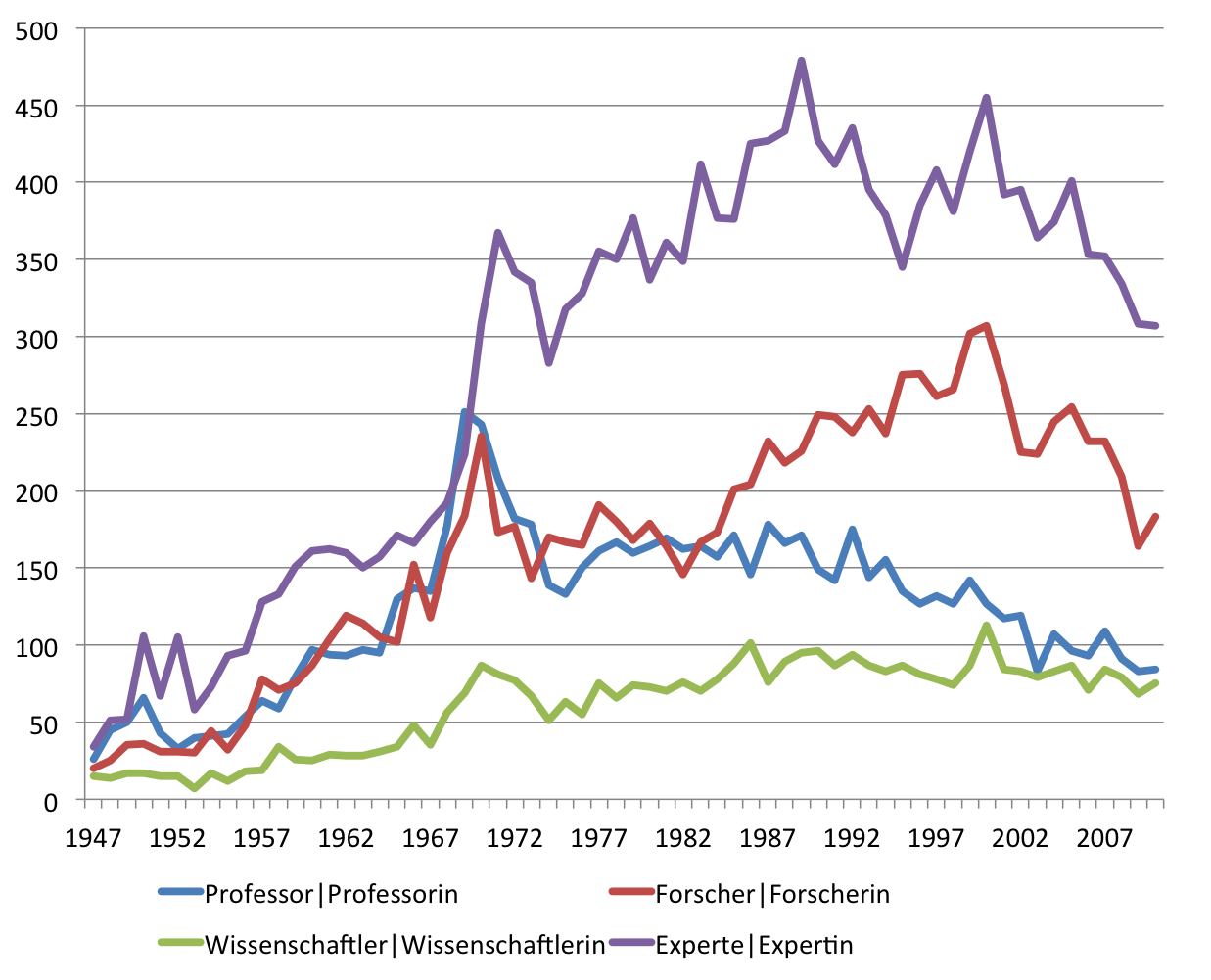
Entwicklung der Frequenz der Komposita (Types), die mit den Wörtern
„Experte“, „Forscher“, „Wissenschaftler“ und „Professor“ gebildet wurden
im SPIEGEL (print) von 1947-2010.
Die Grafik zeigt, dass die größten Veränderungen in den Jahren nach 1968 zu beobachten sind. Hier zeigt sich bei allen Bezeichnungen eine Vermehrung der Anzahl der Komposita, die mit ihnen gebildet wurden, was man als Ausdifferenzierung des Wortschatzes deuten kann. Doch nirgendwo war die Ausdifferenzierung so ausgeprägt wie bei Bezeichnungen für Experten. Die 20 am häufigsten im SPIEGEL auftretenden Experten sind:
Warum 1968?
Die Jahre um 1968 waren eine Zeit, in der Autoritäten überall in der Gesellschaft in Frage gestellt wurden. Natürlich und besonders auch das akademische „Establishment“. Hinzu kam, dass der epistemologische Konsens wegen der Politisierung der Universitäten aufgekündigt wurde: Teile der Wissenschaften wurden pauschal als „bürgerlich“ verunglimpft. Die Konsequenz war, dass der Konflikt zwischen einer „bürgerlichen“ und einer „marxistischen“ bzw. „kritisch-dialektischen“ Wissenschaftsauffassung für die Öffentlichkeit die weltanschaulich-ideologischen Implikationen wissenschaftlicher Erkenntnisse sichtbar machte und damit die Gültigkeit wissenschaftlicher Erkenntnisse relativierte. Der Experte könnte demnach als diskursives Gegengewicht zu vermeintlich „bürgerlichen“ Wissenschaftlern, aber auch als Ergebnis eines allgemeinen Autoritätsverlustes wissenschaftlicher Evidenzkonstruktionen gedeutet werden.
Experten vs. Wissenschaftler
Natürlich werden auch Wissenschaftlerinnen und Wissenschaftler in den Medien als „Experten“ bezeichnet. Dennoch zeigen sich klare Unterschiede in dem, welche Tätigkeiten Wissenschaftlern / Professorinnen / Forschern zugeschrieben werden. Im gedruckten SPIEGEL der letzten zehn Jahre zeigen sich beispielsweise folgende Muster:

Kollokationen zu den Lemmata „Forscher“, „Experte“, „Wissenschaftler“, „Professor“
im gedruckten SPIEGEL (2000-2010)
Die Tätigkeiten, mit denen Experten üblicherweise assoziiert werden sind andere als bei Personen aus dem akademischen Umfeld. Während letztere „messen“, „untersuchen“, „herausfinden“, „entschlüsseln“, „ergründen“, „entdecken“, „nachweisen“, „entwickeln“ und eben „erforschen“, treten Experten mit den Verben „schätzen“, „prognostizieren“, „warnen“, „fürchten“, „bezweifeln“ oder „empfehlen“. Der Experte kommt also immer dann ins Spiel, wenn Wissen als unsicher dargestellt, bewertet und Orientierung aus ihm abgeleitet werden soll. Die Expertise des Experten liegt also nicht im Bereich der Wissensproduktion oder Wissenssicherung, sondern im Bereich der Interpretation von Wissen und der Formulierung von Meinungen, wie mit diesem Wissen umgegangen werden soll. In Wörterbüchern freilich wird „Experte“ als Sachverständiger, Fachmann oder Kenner definiert. Es ist die Spannung zwischen vermeintlich objektiver Sachkenntnis und interessegeleiteter Meinungsproduktion, die die Bezeichnung „Experte“ in den Augen vieler fragwürdig gemacht hat.
Herzlich grüßt euer Sprachexperte Joachim Scharloth
Sprache konstruiert Wirklichkeit. Dies gilt auch für die Sprache, wie sie in der Politik verwendet wird, vielleicht sogar in besonderem Maße. Denn Politikerinnen und Politiker benutzen die wirklichkeitskonstruierende Kraft der Sprache bewusst für ihre politische Agenda. Ob man vom „Betreuungsgeld“ (Regierung) oder der „Herdprämie“ (Opposition), von der „Kopfpauschale“ (SPD, Grüne, Linke) oder dem „solidarischen Bürgergeld“ (CDU/CSU) spricht, jeweils wird der Gegenstand, über den man spricht, in anderer Weise konstruiert und bewertet. Ich würde sogar soweit gehen, zu sagen, dass es nicht einmal mehr derselbe Gegenstand ist, den man von unterschiedlichen Perspektiven durch das Medium der Sprache erfasst, sondern dass durch die unterschiedlichen Bezeichnungen unterschiedliche Gegenstände konstruiert werden. Was Politiker sagen und wie sie es tun, ist also durchaus von Bedeutung für das Verständnis politischer Prozesse.
Auch bei unseren Leitmedien scheint sich diese Erkenntnis durchgesetzt zu haben. In allen Gazetten schreiben Journalistinnen und Journalisten darüber, was Menschen darüber sagen, was andere, mutmaßlich noch wichtigere, Menschen geäußert haben. War das schon immer so? Oder ist das eine Folge des Online-Journalismus mit seiner auf Aktualität getrimmten Kultur, in der jede Äußerung schon eine Meldung wert ist, ohne in größere Nachrichtenzusammenhänge eingebettet zu werden?
Um diese Frage zu beantworten, habe ich mir die Entwicklung der Frequenz von rund 240 Sprachhandlungs- und Kommunikationsverben in drei Textarchiven angeschaut: dem Printarchiv von Spiegel und ZEIT (1947 bis 2010) und dem Archiv von Spiegel Online (2000 bis 2010). Für jeden Artikel habe ich die Frequenz von Kommunikationsverben relativ zur Anzahl der Wörter berechnet, anschließend habe ich den Durchschnitt über alle Artikel eines Jahres gebildet.
Die folgende Abbildung zeigt, dass die Zunahme des Gebrauchs von Kommunikationsverben kein neues Phänomen ist. Schon seit den 1970er Jahren steigt ihr Gebrauch allmählich an. Parallel zu den Anfängen des Online-Journalismus in den 1990er Jahren verstärkt sich jedoch dieser Anstieg. Anders als vermutet, ist die Frequenz bei Spiegel Online auf den ersten Blick nicht dramatisch höher als bei den Print-Medien. (Lesehilfe: Eine relative Frequenz von 0.02 bedeutet, dass jedes 50. Wort ein Kommunikationsverb ist.)

Die Aggregierung der Daten aus allen Ressorts gibt jedoch nur einen recht groben Eindruck. Die ressortspezifische Verteilung von Kommunikationsverben, insbesondere in den Ressorts, die zum Kerngeschäft des Qualitätsjournalismus gehören, erlaubt eine differenziertere Antwort auf die eingangs gestellte Frage. Die folgende Grafik zeigt die Entwicklung der relativen Frequenzen in den Ressorts Deutschland (Spiegel Print), Politik Deutschland (Spiegel Online) und Politik (ZEIT Print; die ZEIT differenziert in ihrer Ressortzuschreibung leider nicht zwischen Innen- und Außenpolitik, weshalb ihre Zahlen nur bedingt mit denen des Spiegel vergleichbar sind).

Es zeigt sich auch hier, dass die Zunahme des Schreibens über das, was andere in der politischen Arena gesagt oder geschrieben haben, kein neues Phänomen ist. Doch ist der Unterschied im Gebrauch von Kommunikationsverben zwischen Print- und Online-Medien hier sehr groß. Interessanterweise ist bei Spiegel Online kein Anstieg der Frequenz zu beobachten. Dies bestätigt sich auch beim Blick auf das Ressort Außenpolitik (für die ZEIT hier wieder die Werte aus dem Ressort Politik).

Auch hier verharren die Zahlen bei SPON auf hohem Niveau, die Printmedien nähern sich dem Online-Medium an. Am stärksten hat die relative Frequenz von Kommunikationsverben jedoch in einem anderen Ressort zugenommen: im Ressort Wirtschaft. Auch hier überlagern offenbar zunehmend Berichte über Gesagtes die Berichterstattung zu messbaren Zusammenhängen, bzw. wird die Präsentation von Fakten an deren Verkündigung gekoppelt.

Man müsste das genauer untersuchen, aber als vorläufiges Fazit lässt sich ziehen: Die Personalisierung von Informationen und die Wiedergabe von Aussagen und Meinungen ist eine immer stärkere werdende Tendenz, die durch die Logik der Online-Medien nicht verursacht, aber verstärkt wurde.
Natürlich sind auch Kommunikationsverben dem Wandel der Moden unterworfen. Im gedruckten Spiegel habe ich mal durchgerechnet, welche Kommunikationsverben für die jeweiligen Jahrzehnte typisch sind (alle signifikant, geordnet nach Frequenzfaktor):
2000er: telefonieren, nerven, mitbekommen, prognostizieren, nachfragen, sagen, mitverfolgen, wetten, lachen, bereuen, mitlesen, reden, nachdenken, kapieren, weinen, bewerten, beten, verklagen, streiten, kritisieren, meckern
1990er: petzen, telefonieren, nerven, kapieren, prognostizieren, mitverfolgen, heucheln, maulen, verfluchen, klagen, meckern, ahnen, drohen, beteuern, warnen, jammern, spekulieren, streiten, beschreiben, bereuen, hetzen, suggerieren
1980er: kritteln, mitverfolgen, denunzieren, anprangern, meinen, petzen, differenzieren, beklagen, bejahen, verhehlen, ermutigen, akzeptieren, beschreiben, nachdenken, bemitleiden, postulieren, bedauern, wiederholen, unterstellen, beteuern
1970er: kritteln, postulieren, bejahen, differenzieren, negieren, geloben, erhoffen, konstatieren, prophezeien, beurteilen, empfehlen, verwahren, verneinen, ermuntern, mitlesen, scheuen, voraussehen, monieren, widerlegen, schildern, vermuten, bezweifeln, denunzieren, diskutieren
1960er: gedenken, befehlen, bejahen, gestatten, bemitleiden, konstatieren, verwahren, verneinen, ermahnen, verhehlen, verbitten, bitten, verabscheuen, widerlegen, antworten, bedauern, empfehlen, geloben, bedenken, ermuntern, unterstellen, feststellen, verraten
1950er: gestatten, gedenken, feststellen, vorschlagen, verneinen, ablehnen, kommentieren, antworten, tippen, befehlen, schreiben, bitten, bedauern, bekennen, verabscheuen, verhehlen, beweisen, versichern, beleidigen, bejahen, nachweisen, verbitten
1940er: tippen, singen, betonen, schreiben, sprechen, verbieten, befehlen, bedauern, gratulieren, antworten, feststellen, nennen, gedenken, schreien, staunen, verklagen, lachen, verurteilen, verabscheuen, ablehnen, wetten, verzeihen, verwahren, kommentieren, bereuen, bekennen
Zuletzt noch ein Schmankerl: Weil alle immer auf das Panorama-Ressort von SPON eindreschen, zum Schluss noch ein Vergleich zwischen den Panorama-Ressorts von Spiegel Online und Spiegel Print („Panorama“ bis 1986, ab 1987 Ressort „Gesellschaft“).

So schlimm ist es also gar nicht mit dem Online-Journalismus. Dazu demnächst mehr auf diesem Blog.
Hier mal eine kleine Illustration, welche Ergebnisse die Wortschatz-Komplexitätsmaße für die Klassifikation von Texten liefern. Als Beispielkorpus habe ich die Texte der militanten gruppe gewählt, weil deren Texte vom BKA schon einmal einer forensischen Analyse unterzogen wurden: einer Analyse im Hinblick auf die Ähnlichkeit mit den Texten eines Soziologen, den man verdächtigte Mitglied der Gruppe zu sein. Dabei sollen Inhaltswörter das Hauptkriterium gewesen sein, wollen uns der Spiegel und andere Medien glauben machen. Die Analyse wurde zu einem jener Indizen, mit denen Überwachung, Festnahme und U-Haft des Soziologen gerechtfertigt wurden. Die folgenden Proberechnungen sind keine ernst zu nehmenden forensischen Analysen, die irgend etwas über die Autoren der Texte der mg aussagen. Sie sollen vielmehr zeigen, wie problematisch der Umgang mit Wortschatz-Komplexitätsmaßen ist. Ich halte es daher auch für unproblematisch, sie zu veröffentlichen.
Die Analyse erfolgte in zwei Schritten: Zuerst wurden für jeden der 52 Texte die Werte Yule’s K, Sichel’s S, Brunet’s W und Honoré’s R berechnet; im Anschluss wurden die Texte auf der Basis der Werte mittels einer hierarchischen Clusteranalyse gruppiert. Die Ergebnisse in Kürze:
Die Clusteranalyse zeigen, wie stark das Maß von der Wortzahl abhängig ist. So finden sich alle längeren Texte im Cluster links, das sich am stärksten von den anderen unterscheidet.

Brunet’s W neigt interessanterweise dazu, die sehr kurzen und die sehr langen Texte als einer Gruppe zugehörig zu klassifizieren.

Im Fall von Sichel’s, das auf der Auswertung von hapax dislegomena beruht, lässt sich keine Hintergrundvariable wie Textlänge, Textsorte oder Entstehungszeit finden, die die Gruppierung der Texte plausibel machen würde.

Gleiches gilt für Yule’s K.

Je nach gewähltem Maß kommen man also zu einer sehr unterschiedlichen Gruppierung der Texte. Auch die Maße, in denen sich keine starken Frequenzeffekte zeigen, differieren in ihren Clustern. Die Interpretation dieser Ergebnisse im Hinblick auf die Autorschaft ist daher mehr als fragwürdig.
| Nr. | Token | Datum | Titel |
|---|---|---|---|
| 0 | 213 | 2001-06-12 | Auch Kugeln markieren einen Schlußstrich … |
| 1 | 1632 | 2001-06-14 | Die „Stiftungsinitiative der deutschen Wirtschaft“ zur Rechenschaft ziehen – Wolfgang Gibowski, Manfred Gentz und Otto Graf Lambsdorff ins Visier nehmen! |
| 2 | 1615 | 2001-06-21 | Anschlagserklärung gegen den Niederlassungszweig der Mercedes-Benz AG auf dem DaimlerChrysler-Werk in Berlin-Marienfelde |
| 3 | 3239 | 2002-02-05 | Anschlagserklärung |
| 4 | 788 | 2002-04-29 | Anschlagserklärung |
| 5 | 569 | 2002-12-31 | Anschlagserklärung |
| 6 | 2032 | 2003-02-25 | Anschlagserklärung |
| 7 | 845 | 2003-10-29 | Anschlagserklärung – Alba in den Müll! Entsorgt Alba! |
| 8 | 1121 | 2003-12-31 | Anschlagserklärung |
| 9 | 1533 | 2004-03-29 | Anschlagserklärung |
| 10 | 1596 | 2004-05-06 | Anschlagserklärung |
| 11 | 1681 | 2004-09-23 | Anschlagserklärung |
| 12 | 816 | 2005-01-10 | Anschlagserklärung |
| 13 | 857 | 2005-04-29 | Anschlagserklärung |
| 14 | 1777 | 2005-11-08 | Anschlagserklärung!!! |
| 15 | 1584 | 2006-02-16 | Anschlagserklärung |
| 16 | 1209 | 2006-03-20 | Anschlagserklärung |
| 17 | 2520 | 2006-04-10 | Anschlagserklärung |
| 18 | 510 | 2006-05-05 | Glückwunschtelegramm & Nachschlag |
| 19 | 844 | 2006-05-23 | Anschlagserklärung |
| 20 | 1139 | 2006-09-03 | Anschlagserklärung |
| 21 | 517 | 2006-09-10 | Anschlagserklärung |
| 22 | 1824 | 2006-10-13 | Dementi & ein bisschen Mehr |
| 23 | 1253 | 2006-12-19 | Anschlagserklärung: Das war Mord! |
| 24 | 419 | 2007-01-14 | Anschlagserklärung |
| 25 | 505 | 2007-05-18 | Anschlagserklärung |
| 26 | 2023 | Winter 2005 | mg-express No.1 |
| 27 | 2114 | Sommer 2006 | mg-express No.3 |
| 28 | 2547 | Herbst 2006 | mg-express No.4 |
| 29 | 2384 | Frühjahr 2007 | mg-express no.5 |
| 30 | 3421 | 2001-11-23 | Ein Debattenversuch der militanten gruppe (mg) |
| 31 | 9093 | 2002-08-01 | Eine Auseinandersetzung mit den Autonomen Gruppen und Clandestino über die Organisierung militanter Gruppenstrukturen |
| 32 | 12021 | Sommer 2005 | Wir haben uns mit einer Menge Puste auf den Weg gemacht |
| 33 | 1494 | 2005-01-29 | Versuch eines Streitgespräches – Reaktion auf das Interview mit Norbert „Knofo“ Kröcher in der Jungle World Nr. 4/26.1.2005 |
| 34 | 1407 | 2005-02-15 | Zum Interim-Vorwort der Nr. 611 vom 10.2.2005 |
| 35 | 1175 | 2005-04-01 | Anmerkungen zum barricada-Interview mit den Magdeburger Genossen |
| 36 | 1859 | 2005-04-01 | Zur jw-Artikelserie „Was tun? In der Stadt, auf dem Land oder Papier: Guerillakampf damals und jetzt“ |
| 37 | 3752 | 2005-06-01 | Zur „postautonomen und konsumistischen“ Sicht auf die Militanzdebatte |
| 38 | 1355 | 2005-07-01 | Was machen wir als militante gruppe (mg) auf einem Sozialforum – haben wir denn nichts Besseres zu tun? |
| 39 | 2912 | 2005-08-01 | Mut zur Lücke? Zu Wolf Wetzels „postfordistischer Protestwelt“ |
| 40 | 8358 | Mitte Mai 2006 | Clandestino – was wollt ihr eigentlich? |
| 41 | 2475 | 2006-06-03 | Zur „Roggan“-Anschlagserklärung der autonomen gruppen |
| 42 | 2993 | 2007-04-11 | Das „Gnadengesuch“ von Christian Klar und der Instrumentalisierungsversuch einer militanten Aktion |
| 43 | 8086 | Ende Mai 2007 | Erklärung zur BWA-Razzia und „Gewaltdebatte“ im Rahmen der Anti-G8-Proteste |
| 44 | 5172 | 2002-05-09 | Für einen revolutionären Aufbauprozess – Für eine militante Plattform |
| 45 | 1859 | 2002-12-19 | Presseerklärung – Nr. 1/2002 |
| 46 | 1841 | 2003-04-17 | Presseerklärung zum revolutionären 1. Mai 2003 in Berlin – Nr. 1/2003 von der militanten gruppe (mg) |
| 47 | 7200 | 2003-06-15 | Ein Beitrag zum Aufruf „27. Juni 1993 – 10 Jahre nach dem Tod von Wolfgang Grams. Glaubt den Lügen der Mörder nicht! Kein Vergeben – Kein Vergessen! Gemeinsam den Kampf um Befreiung organisieren! |
| 48 | 2623 | 2004-06-08 | Eine Nachbetrachtung zum revolutionären 1. Mai 2004 in Berlin |
| 49 | 57053 | 2004-07-01 | Bewaffneter Kampf – Aufstand – Revolution bei den KlassikerInnen des Frühsozialismus, Kommunismus und Anarchismus, 1. Teil |
| 50 | 15696 | 2004-12-01 | (Stadt)guerilla oder Miliz? |
| 51 | 21701 | 2006-01-01 | Kraushaars Buch „Die Bombe im Jüdischen Gemeindehaus“ und die Diskreditierung des bewaffneten Kampfes |


