

Maschinelle Analyse narrativer Muster: Wie Männer und Frauen vom “Ersten Mal” erzählen
Ich hatte mein erstes Mal -> mein erstes Mal mit # -> nahm mich in den Arm -> fragte er mich ob ich -> wir bei ihm zu Hause -> seine Eltern nicht da waren -> kam er auf mich zu -> mich zu küssen und ich -> legten uns auf sein Bett -> fragte mich was los sei -> noch nie einen Freund gehabt -> zogen wir uns gegenseitig aus -> Wir küssten uns leidenschaftlich und -> Dann zog ich ihm seine -> Er schaute mich an und -> schaute mich an und fragte -> an und fragte ob ich -> mit ihm schlafen wolle und -> Er holte ein Kondom aus -> Dann drang er vorsichtig in -> er vorsichtig in mich ein -> Er fragte mich ob ich -> Als er merkte dass ich -> nahm mich in den Arm -> seit # Jahren zusammen und
Diese Phrasen bleiben von einer Geschichte vom „Ersten Mal“, wenn man von ihr das Vereinzelnde, Individualisierende wegnimmt und nur jene Teile der sprachlichen Gestaltung übrig lässt, die auch in anderen Geschichten zum gleichen Thema häufig vorkommen.
Wenn wir unseren Alltag erzählen, dann bedienen wir uns kulturell geprägter Muster. Diese Narrative sind sozial akzeptierte Interpretationsmuster, die unsere Wahrnehmung und Darstellung von Zusammenhängen überhaupt erst ermöglichen, aber gleichzeitig auch begrenzen. Obwohl sie höchst Persönliches und Individuelles zu codieren vorgeben, folgen auch Narrative vom „Ersten Mal“ kulturell geprägten Mustern, denen man sich mit maschinellen Methoden nähern kann. Zusammen mit Noah Bubenhofer und Nicole Müller habe ich 3376 Geschichten vom „Ersten Mal“ auf geschlechtsspezifische Unterschiede hin untersucht.
Sämtliche Geschichten wurden auf den Internet-Plattformen rockundliebe.de (2094 Erzählungen), Erstes-Mal.com (385 Erzählungen) und planet-liebe.de (897 Erzählungen) gesammelt. Die Webseiten wurden automatisiert heruntergeladen, die Texte extrahiert, mit Metainformationen (Alter beim Ersten Mal und Geschlecht) versehen, mit Hilfe des TreeTagger lemmatisiert und mit Part-of-speech-Informationen annotiert. Zusätzlich wurden alle Zahlen durch ein Raute-Symbol ersetzt. Insgesamt umfasst das Korpus 1.886.588 laufende Wortformen. Im Hinblick auf die Dimension Geschlecht ist das Korpus ungleich verteilt: rund 73% der Geschichten stammen von Frauen, nur rund 27% von Männern. Geschichten von Frauen waren mit durchschnittlich 567.9 Wörtern um rund 33 Wörter länger als die von Männern (534.5). Das Durchschnittsalter beim Ersten Mal, wie es von den Autorinnen und Autoren angegeben wurde, lag bei Frauen bei 15.8, bei Männern bei 16.8 Jahren.
Als Analysekategorien dienten uns die Distribution und Verkettung von n-Grammen. Die folgende Tabelle zeigt einen Vergleich der für das jeweilige Korpus typischsten n-Gramme:
| Männer-Korpus | Frauen-Korpus | ||||||
| llr | n-gram | f(1) | f(2) | llr | n-gram | f(1) | f(2) |
| 145,33 | fragte sie mich ob ich | 0 | 54 | 80,84 | drang er in mich ein | 134 | 0 |
| 88,81 | fragte ich sie ob sie | 0 | 33 | 77,82 | ob ich mit ihm schlafen | 129 | 0 |
| 75,36 | drang ich in sie ein | 0 | 28 | 68,97 | fragte er mich ob ich | 167 | 5 |
| 67,28 | Ich fragte sie ob sie | 0 | 25 | 60,93 | in mich ein Es tat | 101 | 0 |
| 64,59 | drang langsam in sie ein | 0 | 24 | 60,93 | legte er sich auf mich | 101 | 0 |
| 64,59 | setzte sie sich auf mich | 0 | 24 | 47,66 | legte sich auf mich und | 79 | 0 |
| 64,59 | und zog es mir ueber | 0 | 24 | 47,66 | und drang in mich ein | 79 | 0 |
| 61,9 | setzte sich auf mich und | 0 | 23 | 45,85 | nahm mich in den Arm | 76 | 0 |
| 59,21 | sie sich auf mich und | 0 | 22 | 44,64 | und legte sich auf mich | 74 | 0 |
| 56,52 | ob ich mit ihr schlafen | 0 | 21 | 44,04 | fing er an mich zu | 73 | 0 |
| 53,83 | Sie fragte mich ob ich | 0 | 20 | 43,43 | er sich auf mich und | 72 | 0 |
| 53,83 | in sie ein Es war | 0 | 20 | 42,83 | in mich ein Es war | 71 | 0 |
| 53,83 | mir ein Kondom ueber und | 0 | 20 | 41,81 | Er fragte mich ob ich | 123 | 6 |
| 53,83 | und ich fragte sie ob | 0 | 20 | 41,02 | und zog es sich ueber | 68 | 0 |
| 51,13 | fluesterte sie mir ins Ohr | 0 | 19 | 40,42 | ihn in mir zu spueren | 67 | 0 |
| 51,13 | ich fragte sie ob sie | 0 | 19 | 40,42 | Er legte sich auf mich | 67 | 0 |
| 48,44 | an mir einen zu blasen | 0 | 18 | 38 | er fragte mich ob ich | 63 | 0 |
| 48,44 | ich drang in sie ein | 0 | 18 | 38 | mich ob ich mit ihm | 63 | 0 |
| 48,44 | legte sich auf den Ruecken | 0 | 18 | 35,59 | fragte mich ob ich es | 59 | 0 |
| 48,44 | mir das Kondom ueber und | 0 | 18 | 34,38 | Ich war mit meinem Freund | 57 | 0 |
Aus diesen Listen wird unter anderem erkennbar, dass die verbale Handlung des Fragens, oder präziser: des Einholens von Einverständnis, offenbar häufig Bestandteil von Erstes-Mal-Erzählungen sind. Ebenso zeigen sich einige wenige geschlechtsspezifische Unterschiede: etwa die Referenz auf die Dauer der Beziehung („Ich war mit meinem Freund“).
Als eine erste Annäherung an die narrative Struktur haben wir die typischen Positionen von n-Grammen in den Texten bestimmt. Hierfür haben wir alle Texte in mehrere jeweils gleich große Teile geteilt und dann untersucht, in welchen Teilen der Erzählungen die n-Gramme mit welcher Frequenz vorkommen. Die folgenden Abbildungen zeigen die Distribution einiger n-Gramme, deren Positionierung im Text geschlechtsspezifische Unterschiede aufweist. Dies sind beispielsweise n-Gramme, die sexuelle Erfahrung und Beziehungsstatus betreffen:
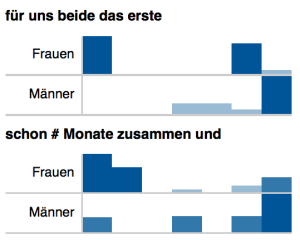
Distribution von n-Grammen in den Geschichten von Männern und Frauen (normalisierte Werte)
Während das n-Gramm „für uns beide das erste“ von Frauen im ersten und vorletzten Abschnitt am häufigsten gebraucht wird, erwähnen Männer die Tatsache, dass es für beide das Erste Mal war, erst am Ende ihrer Erzählungen. Auch das n-Gramm „schon # Monate zusammen und“ wird von Frauen dominant in den ersten Teilen ihrer Geschichten verwendet, Männer hingegen benutzen es am Ende. Eine Kontextanalyse zeigt allerdings, dass bei Verwendung des n-Gramms am Ende einer Erzählung der Geschlechtsakt der Auftakt der Beziehung war, die ihre Fortsetzung bis in die Gegenwart zum Zeitpunkt des Schreibens hat; die Verwendung des n-Gramms zu Beginn einer Erzählung stellt die Dauer der bereits bestehenden Beziehungen dar.
Größere Differenzen in der Distribution zeigen sich auch bei n-Grammen, die auf Schlüsselhandlungen im Kerngeschehen verweisen.
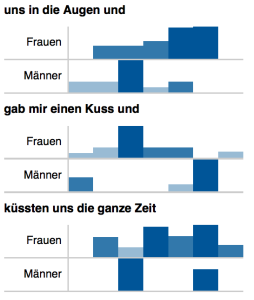
Distribution von n-Grammen in den Geschichten von Männern und Frauen (normalisierte Werte).
So sind die n-Gramme „uns in die Augen und“ und „gab mir einen Kuss und“ je gegensätzlich verteilt. Während in den Erzählungen der Frauen der Kuss am Anfang jener Abschnitte zu finden ist, die sich mit sexuellen Handlungen befassen, berichten Männer hier vorwiegend von Blicken in die Augen; Männer berichten, am Ende der sexuellen Aktivitätsphase geküsst zu werden, Frauen erzählen hier dagegen vom Austausch von Blicken. Dies könnte man so deuten, dass für Frauen mit dem Vollzug des Geschlechtsaktes eine Intensivierung der Beziehung einhergeht, die für den Mann durch die Gabe des Einverständnisses zum Geschlechtsakt durch den tiefen Blick bereits erreicht ist und sich dann im Akt manifestiert. Ein weiterer Aspekt könnte sein, dass Männer narratologisch versichern wollen, dass Einverständnis vorgelegen hat, Frauen dagegen, dass zwischen den Partner emotionale Nähe herrschte. Dies könnte ein Hinweis darauf sein, dass sich aufgrund kultureller Stereotype geschlechtsspezifische Ängste mit dem „Ersten Mal“ verbinden. In diesen Kontext passen auch die Positionsdifferenzen des n-Gramms „küssten uns die ganze Zeit“. Während das fortwährende Küssen in den Erzählungen der Männer Teil von „Vor-“ bzw. „Nachspiel“ zu sein scheint, schildern Frauen ihr Erstes Mal so, dass das Küssen Bestandteil aller Phasen des Kerngeschehens sein kann.
Unser Verfahren zur Rekonstruktion narrativer Muster auf der Makroebene kombiniert typische Musterpositionen mit n-Gramm-Verkettungen (d.h. kookkurierenden n-Grammen) und visualisiert sie als hierarchischen Graphen. Der folgende Graph (hier als PDF zum Vergrößern), der Tetragrammverkettungen in den Geschichten von Frauen illustriert, bildet die Abfolge von Mustern in der vertikalen Dimension (von oben nach unten) ab. Mehrere voneinander unabhängige narrative Muster im gleichen Abschnitt, das heißt an ähnlichen Erzählpositionen, werden nebeneinander dargestellt. In diesem Graphen sind Bereiche von geringer phraseologischer Durchdringung und Verdichtungsbereiche sichtbar.
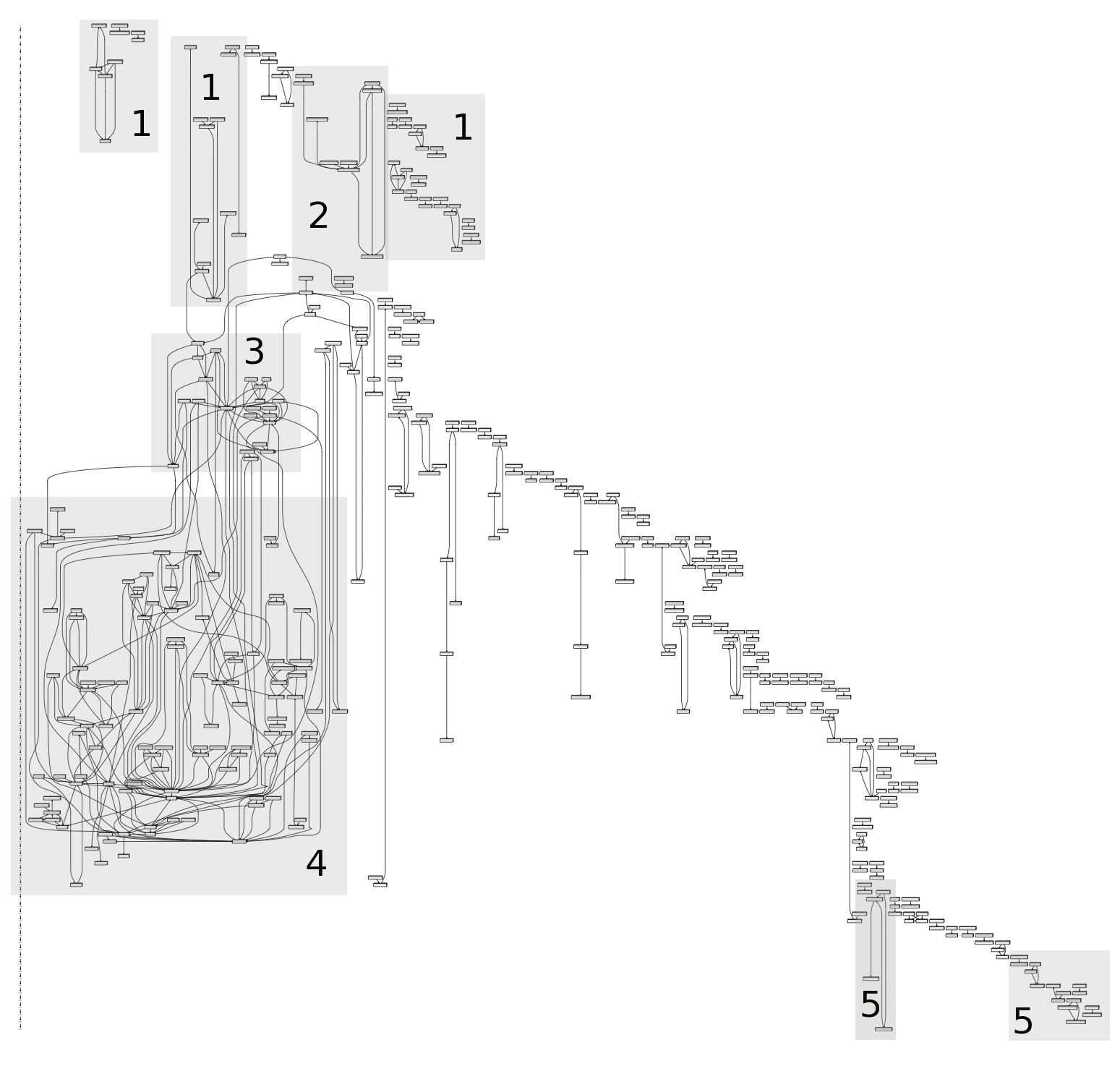
Narrationsgraph für die Erzählungen von Frauen
Muster in 1 referieren auf das Alter der Hauptpersonen der Erzählung:
Mein erstes Mal hatte – ich mit meinem Freund – hatte ich mit # – erstes Mal mit # – Bei meinem ersten Mal – ersten Mal war ich – Freund und ich waren – Ich war damals # – Ich war # und – # und er war – älter als ich und – ist # Jahre älter
Muster in 2 referieren auf die Dauer der Beziehung:
# Monate mit meinem – Monate mit meinem Freund – # Wochen mit meinem – mit mei-nem Freund zusammen – # Monate mit ihm – Monate mit ihm zusammen
Muster in 3 referieren auf die Frage des Mannes nach dem Einverständnis:
schaute mir tief in die – schaute mir lange in die – in die Augen und – fragte mich ob ich – Er fragte mich ob – mit ihm schlafen – ich es wirklich will – ich es wirklich wollte
Muster in 4 referieren auf das sexuelle Geschehen, in dem vor allem der Mann aktiv ist:
Er holte ein Kondom – Kondom aus seiner Hosentasche – aus seiner Tasche – Kondom aus seinem Nachttisch – holte ein Kondom raus – und streifte es sich – zog es sich über – sich über und drang – ganz vorsichtig in mich – langsam und vorsichtig in – langsam in mich ein – drang in mich ein – in mich ein Es – Es tat überhaupt nicht – tat überhaupt nicht weh
Muster in 5 referieren auf den gegenwärtigen Beziehungsstatus:
Und wir sind immer – immer noch zusammen und – immer noch mit ihm – noch mit ihm zusammen – Schatz ich liebe dich – liebe dich über alles
Die Umrisse der typischen Erzählung vom Ersten Mal aus der Sicht von Frauen werden anhand dieses Verfahrens gut sichtbar. Alternative Erzählstränge, die sich teilweise paral-lel zu den grau hinterlegten Teilen befinden, beziehen sich auf die Aspekte Schmerz („erst tat es ein“, „ein bisschen weh aber“, „dann war es einfach“, „es einfach nur noch“), praktische Unerfahrenheit („versuchte in mich einzudringen“) und die Evaluation („Es war ein wunderschönes“, „Es war ein unbeschreibliches“, „war ein unbeschreibliches Gefühl“, „Ich hätte nie gedacht“).
Aus dem folgenden Narrationsgraph (hier als PDF zum Vergrößern), der die Muster aus männlicher Perspektive verfasster Geschichten visualisiert, will ich nur zwei Auffälligkeiten aufgreifen.
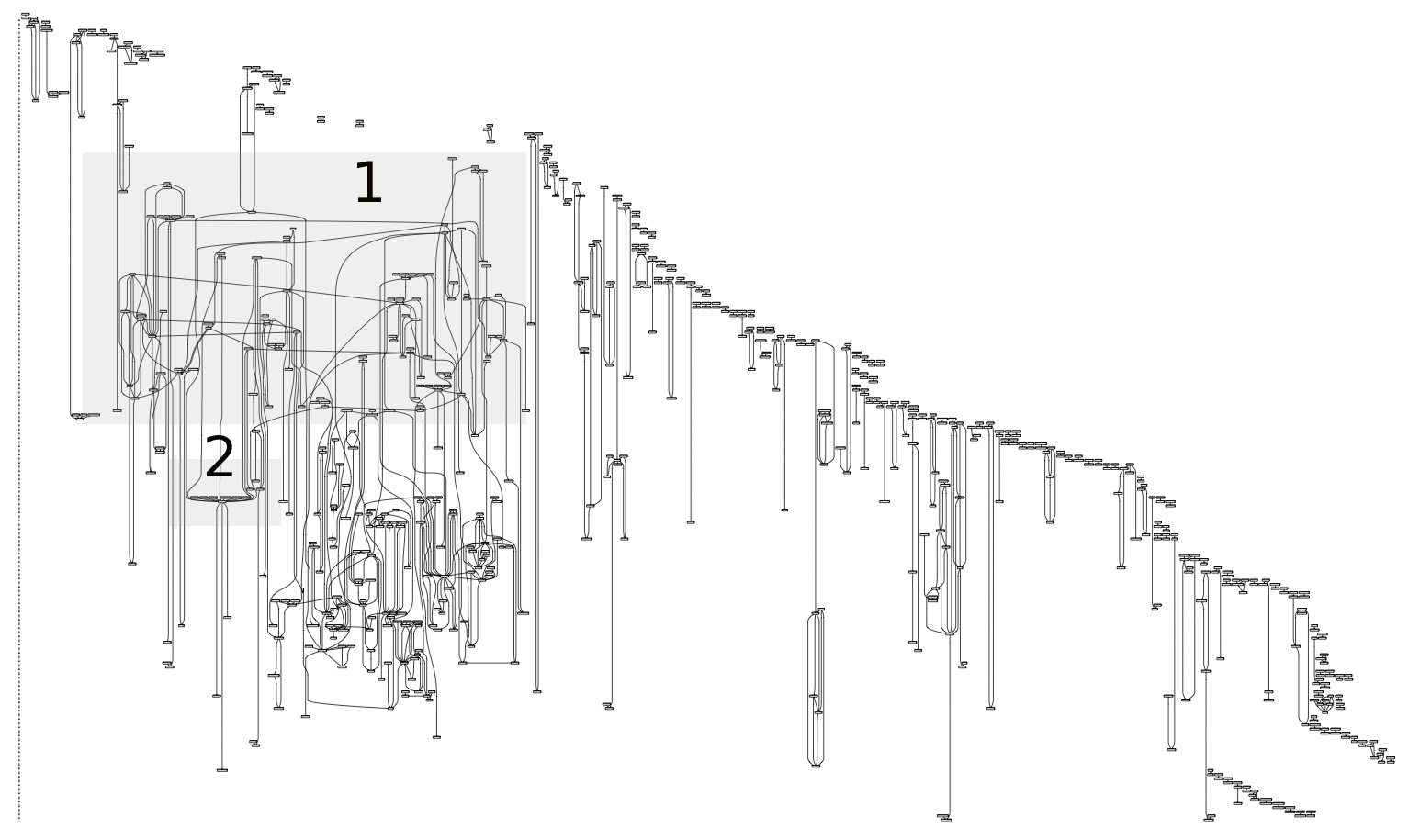
Narrationsgraph für die Erzählungen von Männern
Zum einen sind dies jene sprachlichen Muster im mit 1 bezeichneten Bereich, die auf die Einholung des Einverständnisses zum Geschlechtsakt verweisen. Hier ist es so, dass die Frage von männlicher wie weiblicher Seite kommen kann („fragte sie mich ob“, „ich fragte sie ob“). Zum anderen findet sich im mit 2 bezeichneten Bereich (siehe die nächste Abbildung) eine auffällige Verbindung mehrerer n-Gramme mit der Mehrworteinheit „Sie meinte ich solle“.
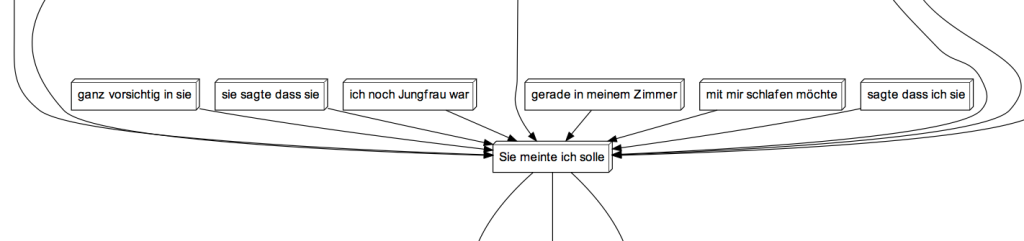
Ausschnitt aus dem Narrationsgraphen der Männer
Die Analysen zeigen, dass Geschichten vom Ersten Mal von Männern und Frauen recht ähnlich erzählt werden und zwar nicht nur im Hinblick auf das sexuelle Geschehen, sondern auch im Hinblick auf die verbalen Handlungen, die ihm vorausgehen und es begleiten. Zentraler Bestandteil typischer Erzählungen beider Geschlechter ist die verbale Verständigung über die Bereitschaft zum Geschlechtsakt und die explizite Gabe des Einverständnisses durch die Frau. Das von der Paarsoziologie als Schwellen-Wendepunkt bezeichnete Erste Mal wird also als eine durch Einverständnis der Frau legitimierte Handlungsfolge erzählt, in der der Mann mehr Handlungsmacht hat als die Frau.
Die Ergebnisse der Analyse haben wir in folgendem Artikel zusammengefasst, den es auch als Preprint gibt:
30C3 Nachlese
Der 30. Chaos Communication Congress war ein buntes Treffen von Makern, Netzaktivisten, Old-style-Hackern, DIYern und IT-Sicherheitsspezialexperten, das ganz im Zeichen der Snowden-Leaks stand. Auch wenn Zynismus, Wut und Trotz die gängigen Modi im Umgang mit der Totalüberwachung digitaler Kommunikation sind, überwog in den meisten Vorträgen doch der analytische Blick auf technische, politische und soziokulturelle Folgen der systematischen Grundrechtsverletzung durch staatliche Akteure.

Trotz der großen Vielfalt waren Kontroversen kaum sichtbar. Die Snowden-Enthüllungen haben es schwer gemacht, Datenschutz für gestrig zu erklären und die Abschaffung der Privatsphäre gut zu finden. Die Community wird nicht nur über einen computerzentrierten Lebensstil zusammengehalten. Sie ist sich einig in der Forderung nach Einhaltung von Grundrechten, im Kampf für ein Recht auf Anonymität, um transparente staatliche Institutionen und ein freies Netz. Und die Community weiß, was zu tun ist: offene technische Lösungen für möglichst spurenarme und sichere Kommunikation entwickeln, konstruktiv auf demokratische Entscheidungsprozesse und gesellschaftliche Debatten einwirken und wo das nichts nützt, sich an Protesten zu beteiligen, auch aktionistisch.
Der CCC ist nicht das revolutionäre Subjekt, von dem manche zu träumen scheinen. Er ist das organisatorische Rückgrat eine Community, die meistens still (und leider manchmal auch etwas unkoordiniert), aber beharrlich an ihren Projekten arbeitet. Er bezieht sein öffentliches Gewicht aus der technischen Kompetenz seiner Mitglieder und nicht daraus, dass er meinungsstark auf der Klaviatur der sozialen Medien spielt. Er ist keine straff organisierte NGO und schon gar keine Kaderorganisation. Dieser Einsicht ist es wohl auch zu verdanken, dass Versuche von Interessengruppen, die öffentliche Aufmerksamkeit und das Prestige des CCC für ihre Ziele zu benutzen, in diesem Jahr ausblieben.
Und so sind es auch nicht die Talks mit Glamourfaktor in Saal 1, in denen teilweise mit viel Pathos die Gegenwart und Zukunft des Netzes verhandelt wurde, die diesen Kongress ausgemacht haben, sondern die vielen Assemblies und Workshops, die Lightning Talks und zahlreichen Gespräche in den Lounges. Die meisten Teilnehmer dürften müde, aber mit dem Kopf voller Ideen nach Hause gefahren sein.
Ich habe auch gleich am Anfang einen Vortrag zum Thema „Überwachen und Sprache“ halten dürfen, den man sich hier herunterladen oder hier anschauen kann:
Stefan Schulz hat für die FAZ einen schönen Artikel über meinen Vortrag geschrieben, der vieles klarer formuliert als es mir möglich war. Heise hat dem Thema einen Spin gegegeben, der von mir nicht intendiert ist. Und der Deutschlandfunk geht in seinem Bericht weiter als ich in seiner Interpretation meines Vortrags. Und Al Jazeera hat einen kurzen O-Ton von mir eingeholt:
Einige inhaltliche Klarstellungen zu meinem Vortrag liegen mir am Herzen:
- Die „Software“, die in meinem Vortrag vorkommt, existiert nicht und ist natürlich rein fiktional.
- Ich habe nicht gesagt, dass Fefe oder Don Alphonso die radikalsten Blogger im ganzen Land sind. Die präsentierten Berechnungen dienten lediglich dazu, die Methoden zu illustrieren und zu verdeutlichen, dass die Zuschreibung von Kategorien wie „Gefährder/in“ oder „Radikale/r“ auf der Basis von Theorien und Methoden erfolgt, die sich nicht rechtfertigen müssen.
- Ich analysiere keine Wortwolken, wie der Deutschlandfunk in seinem Bericht über meinen Vortrag erklärte, sondern Kollokationsgraphen im Sinne der visual analytics. Die Metapher der Wortwolke ist in diesem Kontext etwas irreführend.
- Ich gehöre natürlich auch nicht zum „Schwarzen Block des CCC“, wie ein Mitglied von seniorentreff.de mutmaßt, ich hatte nur einen schwarzen Kapuzenpullover an (aber ansonsten Bluejeans und beige Chucks…).
Und dann war auch noch Promi-Gucken angesagt: Einmal habe ich hinter Andi Müller-Maguhn in der Schlange gestanden, bin neben Fefe die Treppe runtergelaufen und mit Constanze Kurz Aufzug gefahren. Außerdem konnte ich Marcus Richter und Tim Pritlove in Aktion erleben, deren Stimme mir viele Zugfahrten in der Tokyoter Rushhour erträglich gemacht haben. Ein großer Dank an alle Organisatorinnen und Organisatoren und an die Scharen von Engeln, die diesen Kongress möglich gemacht haben! Bis nächstes Jahr!

Rechtsextremismus und die Mitte der Gesellschaft: Kulturalismus, Populismus und Skandalisierung
Liebe Freunde der Sicherheit,
vom Landesamt für Verfassungsschutz in Sachsen wurde ich eingeladen, auf einer Tagung einen Vortrag zum Thema „Rechtsextremismus und die Mitte Gesellschaft“ aus sprachwissenschaftlicher Sicht zu halten. Weil ich das Thema relevant finde, habe ich zugesagt. Im Folgenden findet ihr die Analysen, die ich für diesen Vortrag durchgeführt habe.
Grundannahmen
Sprache konstruiert Wirklichkeit. Je nach dem, ob wir einen Gegenstand als „Herdprämie“ oder „Erziehungsgeld“ bezeichnen, heben wir unterschiedliche Aspekte an ihm hervor (Erziehung vs. Frauenpolitik), wecken spezifische Assoziationen (Anerkennung bislang nicht honorierter Leistungen vs. traditionelle Geschlechterrollen), verbinden unterschiedliche Handlungsaufforderungen mit ihm (Zustimmung vs. Ablehnung) und konstruieren ihn so auf je unterschiedliche Weise. Derjenige Akteur, der seinen Sprachgebrauch zur Norm erheben kann, dessen Handeln erscheint als konsistent und legitim. Sprachliche Wirklichkeitskonstruktionen erfolgen jedoch nicht über das Prägen von Bezeichnungen alleine, sondern auch im Kontext von längeren Aussagen und Aussagezusammenhängen.

Beispiel: Kollokationen zum Lemma „Ausländer“ in rechtsextremen Foren (Ausschnitt)
Eine Möglichkeit, die spezifischen Wirklichkeitskonstruktionen zu messen ist die Kollokationsanalyse, also die Analyse, welche Wörter überzufällig häufig miteinander auftreten. Wenn beispielsweise „Nerd“ häufig mit „Außenseiter“, „IQ“, „sozial“ und „gestört“ auftritt, dann verrät dies etwas darüber, wie die kulturelle Entität „Nerd“ konstruiert wird.
Vorgehensweise
Ich habe aus zwei rechtsextremen Internet-Diskussionsforen (Forum Deutscher Netzdienst, ein zwischen 2003 und 2009 von der NPD betriebenes Forum) und dem neonazistischen Thiazi-Forum (2007-2012) ein Korpus mit rund 500 personenspezifischen Teilkorpora erstellt. Das Korpus umfasst rund 25 Millionen Wörter. In diesem Korpus habe ich typische Wortverbindungen berechnet. Nun ist natürlich nicht jede Wortverbindung in diesem Korpus gleich ein Indikator für rechtsextreme Gesinnungen: Nazis schlagen nicht nur Fenster, sondern auch Wege ein und die Verbindung von „Weg“ und „einschlagen“ findet sich in Texten „der Mitte“ genauso wie bei Rechtsextremen. Um ein Kriterium für die Ideologizität der Kollokationen zu haben, habe ich mich dafür entschieden, nur solche als Indikatoren für Rechtsextremismus anzusehen, in denen NPD-Schlagwörter vorkommen. NPD-Schlagwörter habe ich identifiziert, indem ich Pressemitteilungen der NPD mit Pressemitteilungen von CDU und SPD verglichen habe.

Typische Lemmata in den Pressemitteilungen der NPD
im Vergleich zu den Pressemitteilungen von CDU und SPD (Auswahl)
Um beantworten zu können, in welchen Bereichen „die Mitte“ offen ist für rechtsextremes Gedankengut, brauchte ich ein Vergleichskorpus. Weil das Konzept der „Mitte“ nicht klar bestimmbar ist, ist meine Wahl auf ein Online-Diskussionsforum gefallen, das plural im Hinblick auf die dort vertretenen politischen Ansichten ist: politikforum.net. Auch hier habe ich ein Korpus aus 577 personenspezifischen Teilkorpora gebildet, das rund 27 Millionen Wörter umfasst. Das ist zwar nicht Big Data, aber schon recht aussagekräftig (zum Vergleich: Der Zauberberg hat rund 300.000 Wörter). Auch für dieses Korpus habe ich Kollokationen berechnet.

Kollokationen zum Lemma „Sozialsystem“ im Vergleich: NPD-Forum vs. politikforen.net
(Schlagwörter der NPD in zwartem rosa)
Offenheit für rechtsextremes Gedankengut habe ich dann darüber berechnet, wie hoch der Anteil von Kollokatoren ist, die beim gleichen Lemma auch bei der NPD Kollokatoren sind, und wie hoch der Anteil von NPD-Schlagwörtern unter den Kollokatoren ist. Schließlich habe ich die Wörter auf der Basis der Kohärenz der in ihnen vorkommenden Kollokationen thematisch gruppiert und als Graphen visualisiert.
Ergebnisse
In welchen Bereichen gibt es also teilweise Übereinstimmungen in den Denkweisen von Rechtsextremisten und der „Mitte der Gesellschaft“? Zunächst einmal finden sich ein paar übliche Verdächtige: Bei den Themen Ausländer / Migration, Islam und Kriminalität konvergiert der Sprachgebrauch in politikforen.net stark mit dem Sprachgebrauch im NPD-Forum.
Das Thema Ausländer / Migration nimmt von den Schnittmengenthemen den größten Raum ein und wird konstituiert durch die Lemmata Abschiebung, Assimilation, südländisch, Gastrecht, ausweisen, integriert, Ausweisung, Ausländer, Migrationshintergrund, Herkunft, nichtdeutsch, Ethnie, Angehörige, Leitkultur, überschwemmen, Zugehörigkeit, Nichtdeutsche, Bande, geboren, ausnutzen, abschieben, Abstammung, nicht-deutsch, ausländisch, Überfremdung, Multikulti, Migration, Migrant, strömen, Heimat, Identität, ertappt, Minderheit, Integration, Elternteil, Asylant, begrenzen, Investor, aussehend, Sozialhilfeempfänger, Sitte, einwandern, kürzen, Rasse, Urbevölkerung, Masseneinwanderung, Rückkehr, Zuzug, Südland und Mentalität sowie durch die Bezeichnungen für einzelne ethnische Gruppen.
Die typischen Verwendungsweisen des Lemmas „Gastrecht“ in politikforen.net illustriert die Nähe zu rechtsextremem Gedankengut.

Kollokationsgraph zum Lemma „Gastrecht“ in politikforen.net. Braune Knoten
markieren Schlagwörter der NPD, braune Kanten verweisen darauf,
dass die Wortverbindung auch in rechtsextremen Diskussionsforen auftritt.
Das Thema Kriminalität ist nach dem Thema Ausländer / Mirgation das am breitesten diskutierte Thema und wird konstituiert durch die Lemmata straffällig, kriminell, Gewalttat, Kriminelle, gewalttätig, Delikt, Gewalttäter, Straftat, Straftäter, Kriminalitätsrate, Tatverdächtige, Täter, lebenslang, abstechen, gewaltbereit, Bewährung, abschreckend, Kriminalität, Bestrafung, bestrafen, begangen, liegend, Todesstrafe, Statistik, Verbrecher, wegsperren und Mord. Im Folgenden ein Ausschnitt aus dem Kollokationsgraph zum Lemma „kriminell“ in politikforen.net.

Kollokationsgraph zum Lemma „kriminell“ in politikforen.net (Ausschnitt).
Braune Knoten markieren Schlagwörter der NPD, braune Kanten verweisen darauf,
dass die Wortverbindung auch in rechtsextremen Diskussionsforen auftritt.
Ein bemerkenswerter Teilbereich mit großer Konvergenz sind Sexualverbrechen, insbesondere Kindesmissbrauch.

Kollokationsgraph zum Lemma „Vergewaltiger“ in politikforen.net (Ausschnitt).
Braune Knoten markieren Schlagwörter der NPD, braune Kanten verweisen darauf,
dass die Wortverbindung auch in rechtsextremen Diskussionsforen auftritt.
Die Themenfelder Ausländer / Migration und Kriminalität werden in politikforen.net ebenso wie in den rechtsextremen Foren häufig miteinander verschränkt, wie der Kollokationsgraph zu „nichtdeutsch“ illustriert.

Kollokationsgraph zum Lemma „nichtdeutsch“ in politikforen.net (Ausschnitt).
Braune Knoten markieren Schlagwörter der NPD, braune Kanten verweisen darauf,
dass die Wortverbindung auch in rechtsextremen Diskussionsforen auftritt.
Basis für die Themen Ausländerfeindlichkeit in Verbindung mit Kriminalität und Islamophobie / antimuslimischem Rassismus ist eine Ideologie, die ich als Kulturalismus bezeichnen möchte. In ihr werden Menschen als durch ihre Kultur determinierte Wesen konzeptualisiert und kulturelle Unterschiede als unveränderbar und damit unüberwindlich angesehen. Sichtbar wird Kulturalismus im Kollokationsgraphen zum Lemma „Kultur“:

Kollokationsgraph zum Lemma „Kultur“ in politikforen.net (Ausschnitt).
Braune Knoten markieren Schlagwörter der NPD, braune Kanten verweisen darauf,
dass die Wortverbindung auch in rechtsextremen Diskussionsforen auftritt.
„Kultur“ wird als eine an ein Volk gebundene, von Vermischung bedrohte Lebensweise konzeptualisiert, zu der als Prädikat „grundverschieden“ hinzutreten kann. Der Kulturbegriff hat auch im akademischen Diskurs die Funktion, Homogenität zu konstruieren. Auch in den Diskussionsforen ist die Homogenitätsideologie Bestandteil des Kulturalismus:

Kollokationsgraph zum Lemma „homogen“ in politikforen.net (Ausschnitt).
Braune Knoten markieren Schlagwörter der NPD, braune Kanten verweisen darauf,
dass die Wortverbindung auch in rechtsextremen Diskussionsforen auftritt.
Neben den Wörtern „Kultur“ und „homogen“ sind es die folgenden Lemmata, die das Feld des Kulturalismus abstecken und in der rechtsextremer Sprachgebrauch mit dem Sprachgebrauch in politikforum.net konvergiert: Abstammung, Volk, Multikulti, Kulturkreis, Heimat, Identität, Minderheit, bewahren, Sitte, zugehörig, Rasse, Lebensweise, aufgeben, Urbevölkerung, vermischen und Mentalität. Eine genauere Analyse würde zeigen, dass der Kulturalismus die Bedingung für die diskriminierenden Konstruktionen in den Themenfeldern Ausländer / Migration, Kriminalität und Islam ist.
Einher mit dem Kulturalismus geht in rechtsextremen wie pluralistischen Diskussionsforen die Legitimierung von Etabliertenvorrechten. Einheimische genießen Vorrechte gegenüber Zugezogenen, Völker leben in ihrer angestammten Heimat:

Kollokationsgraph zum Lemma „angestammt“ in politikforen.net (Ausschnitt).
Braune Knoten markieren Schlagwörter der NPD, braune Kanten verweisen darauf,
dass die Wortverbindung auch in rechtsextremen Diskussionsforen auftritt.
Eine weitere semantische Grundfigur, die rechtsextremes Denken in „der Mitte“ der Gesellschaft anschlussfähig macht, ist die argumentative Inanspruchnahme der (schweigenden) Mehrheit der Gesellschaft.

Kollokationsgraph zum Lemma „Mehrheit“ in politikforen.net (Ausschnitt).
Braune Knoten markieren Schlagwörter der NPD, braune Kanten verweisen darauf,
dass die Wortverbindung auch in rechtsextremen Diskussionsforen auftritt.
Zusammen mit einer pauschalen Kritik an der politischen Klasse („korrupt“ und „unfähig“) sind die typischen Ingredienzien des Populismus versammelt.

Kollokationsgraph zum Lemma „Politiker“ in politikforen.net (Ausschnitt).
Braune Knoten markieren Schlagwörter der NPD, braune Kanten verweisen darauf,
dass die Wortverbindung auch in rechtsextremen Diskussionsforen auftritt.
Eine letzte semantische Grundfigur, die die Debatten in rechtsextremen wie pluralistischen Foren verbindet, ist die Tendenz zur Skandalisierung, die in beinahe allen genannten Themenbereichen präsent ist.

Kollokationsgraph zum Lemma „asozial“ in politikforen.net (Ausschnitt).
Braune Knoten markieren Schlagwörter der NPD, braune Kanten verweisen darauf,
dass die Wortverbindung auch in rechtsextremen Diskussionsforen auftritt.
Ich konnte hier nicht alle Bereiche und schon gar nicht in der gewünschten Ausführlichkeit vorstellen. Auch erinneringspolitische Themen wie die Wehrmacht und die Vertreibung aus den ehemaligen deutschen Ostgebieten, aber auch Sozialpolitisches, antikapitalistisch angehauchte Bankenkritik und die Einschränkung von Grundrechten sind Themen, in denen sich rechtsextreme Positionen mit Mittepositionen berühren. Funfact am Rande: auch die Ansichten über den Verfassungsschutz konvergieren in extremistischen und pluralistischen Diskussionsforen.

Themenfelder und semantische Grundfiguren, die eine hohe Kongruenz
mit rechtsextremen Diskursen aufweisen.
Die obige Grafik ist der Versuch, Themenfelder und semantische Grundfiguren zu ordnen.
Neben den erwartbaren Ergebnissen, dass Ausländerfeindlichkeit, Politikverdrossenheit und Kriminalität Türen sind, durch die rechtsextreme Positionen in weiteren Teilen der Gesellschaft eindringen können, zeigt die Analyse, dass auch semantische Grundfiguren des Populismus, der Skandalisierung und vor allem des Kulturalismus der Nährboden für das Gedeihen rechtsextremen Gedankengutes in „der Mitte der Gesellschaft“ sein können.
Parlando – Monitoring des Sprachgebrauchs im Sächsischen Landtag
Liebe Freunde der Sicherheit,
zusammen mit meinem Kollegen Noah Bubenhofer habe ich ein Monitoring des Sprachgebrauchs im Sächsischen Landtag entwickelt.

Es ist unter http://linguistik.zih.tu-dresden.de/parlament/ benutzbar. Viel Spaß beim Herumklicken!
Kulturwissenschaften im Data-driven Turn: Zeitgeschichtliche Umbrüche in der ZEIT
Liebe Freunde der Sicherheit,
Die Kultur- und Sozialwissenschaften befinden sich im Data-driven Turn. Das Arbeiten mit datengeleiteten Methoden steckt zwar noch in den Kinderschuhen, sein Potenzial wird aber immer sichtbarer und beflügelt die Phantasien von Wissenschaftlerinnen und Wissenschaftlern. Die Fortschritte in der Digitalen Bildverarbeitung ermöglichen es den Bildwissenschaften, typische Konfigurationen in visuellen Darstellungen datengeleitet zu ermitteln; der Wandel von Musik wird anhand von strukturentdeckenden Verfahren über große Mengen digitaler Musikstücke berechenbar; die Geschichteswissenschaft erfindet sich unter dem Label „Data Driven History“ neu; in der Soziologie werden Daten aus sozialen Netzwerken dazu benutzt, die lebensstilsspezifische Gliederung sozialer Gemeinschaften aufzudecken; und in der Kunstgeschichte lassen sich auf der Basis bildspezifischer Figurationen Kunstgeschmäcke, Sujets oder ganze Kunststile berechnen. Diese Entwicklungen haben das Potenzial, die Kultur- und Sozialwissenschaften nachhaltig zu verändern, weshalb wir von einem Data-driven Turn sprechen wollen.
Datengeleitete Methoden
Data-driven heißt, auf vorgängige Hypothesen zu verzichten, induktiv Strukturen in den Daten zu ermitteln und im erst im Anschluss zu kategorisieren und zu interpretieren. Dadurch geraten Evidenzen in den Fokus, die entweder quer zu den vorher existierenden Erwartungen stehen und die Grundlage für neue Erklärungsmodelle sein können, oder im besten Fall sogar solche Evidenzen, die die Bildung alternativer Analysekategorien nahelegen. Für die Kultur- und Sozialwissenschaften bedeutet der Data-driven Turn, dass sie ihren Datenhunger nicht mehr mit Hinweis auf forschungspraktische Grenzen (begrenzte Ressourcen für Lektüre und Codierung) limitieren müssen. Je mehr Daten, desto besser! Das bedeutet freilich auch: hermeneutische oder dekonstruktive Lektüre jedes einzelnen Exemplars ist unmöglich.
Beispiel: Frames im ZEIT-Archiv
Zusammen mit David Eugster und Noah Bubenhofer habe ich mir das ZEIT-Archiv (1946-2011) vorgenommen, um zu untersuchen, ob sich zeitgeschichtliche Umbrüche berechnen lassen. Hierfür haben wir die Veränderung des Auftretens von Frames und ihrer Vernetzung untersucht. Mit dem Ausdruck „Frame“ bezeichnen wir Interpretationsschemata, mit deren Hilfe wir Erfahrungsdaten verarbeiten. Durch Framing werden Informationen für uns überhaupt erst sinnhaft. Wir beschäftigen uns im Folgenden also mit dem Wandel von Realitätskonstruktionen in der Wochenzeitung DIE ZEIT. Frames werden durch bestimmte Indikatoren aktiviert — wir haben sie anhand der Distribution von Lemmata in Zeitungstexten identifiziert.
Umbrüche
Umbrüche nennen wir jene Zeiträume, in denen sich besonders große Verschiebungen im Frame-Haushalt beobachten lassen. Wir haben sie anhand der jahresweisen Differenzbeträge berechnet: einmal mit relativen Frame-Frequenzen, einmal mit normalisieren relativen Frame-Frequenzen. Während bei der Berechnung der Differenzbeträge der relativen Frequenzen die hochfrequenten Frames ein höheres Gewicht haben, werden bei der Berechnung der Differenzbeträge der normalisierten Frequenzen alle Frames gleich gewichtet. Wie die folgende Grafik belegt, führen aber beide Berechnungsmethoden zu ähnlichen Ergebnissen:

Jährliche Summen der Differenzbeträge aller Frames im Vergleich zum Vorjahr
im Print-Archiv der ZEIT, 1946-2011. Oben: relative Frequenzen,
Unten: normalisierte relative Frequenzen.
Die Grafiken zeigen, dass in den Jahren 1957-1959 (mit Schwerpunkt 1959), 1970, 1981, 1992 und 2008-2010 (mit Schwerpunkt 2008) besonders starke Veränderungen im Framehaushalt im Vergleich zu den Vorjahren zu beobachten sind. Auch die Jahre 2001-2003 können, wenn auch leicht abgeschwächt, als Jahre der Veränderung gelten. Diese Zunahmen im Differenzbetrag deuten wir als Indikatoren für eine starke Veränderung in der semantischen Matrix und damit als Umbrüche im oben beschriebenen Sinn. Insbesondere bei den Umbrüchen von 1969/70, 1980/81 und 1991/92 sind in den folgenden Jahren nur vergleichsweise geringe Veränderungen zu beobachten, während nach den Umbruchjahren 1957-1959 und 2008-2010 eine allmähliche Verringerung der Variation zu beobachten ist.
Einige dieser anhand der Frameanalyse identifizierten Umbruchjahre lassen sich auf zeitgeschichtliche Ereignisse und Entwicklungen beziehen: der Umbruch von 1969/70 könnte als Folge der 68er-Bewegung gedeutet werden, die Veränderungen von 1991/92 als Nachwirkung der deutschen Einheit, die Variation in den Jahren 2001 bis 2003 als Effekt der Terroranschläge vom 11. September 2001 und die starken Veränderungen nach 2008 als Folge der Finanz- und Wirtschaftskrise. Bei den Umbruchjahren 1957 bis 1959 und 1980/81 ist es jedoch schwieriger, eine plausible zeithistorische Begründung zu finden. Können hier Wiederbewaffnung und Diskussion um die Ausstattung der Bundeswehr mit Atomwaffen, europäische Integration (1957-1959) und NATO-Doppelbeschluss und Friedensbewegung (1980/81) als Erklärung herangezogen werden?
Detailanalyse
Diese Fragen lassen sich nur beantworten, wenn man detailliert untersucht, welche Framekonstellationen sich in den Umbruchsjahren besonders stark verändern. Wir haben die Veränderungen mit Hilfe von Kollokationsgraphen visualisiert, was ich im Folgenden am Beispiel des Umbruchs 1991/1992 illustrieren will: Wir haben einen Frame-Kollokationsgraphen für den ersten Zeitabschnitt (1991) und einen für den zweiten Zeitabschnitt (1992) berechnet und die beiden Rhizome zu einem gemeinsamen Graphen vereint, in dem die spezifischen Frame-Kollokationen der Umbruchjahre hervorgehoben sind. Wie die folgende Abbildung zeigt, lassen sich in diesem Graphen drei Cluster identifizieren, in denen besonders viele für das Umbruchjahr 1992 spezifische Frame-Kollokationen verdichten.

Frame-Kollokationen im ZEIT-Archiv der Jahre 1991 und 1992.
Spezifische Frame-Kollokationen des Jahrs 1992 sind schwarz hervorgehoben.
Besonders interessant erscheint uns das Cluster 2, das sich um die Frames „Freiheit“ und „Nation“ formiert.

Frame-Kollokationen im ZEIT-Archiv der Jahre 1991 und 1992, Cluster 2.
Spezifische Frame-Kollokationen des Jahrs 1992 sind schwarz hervorgehoben.
Der Frame „Nation“ ist dabei erwartbar stark verbunden mit dem „Freiheits“-Frame, welcher wiederum soziologische Frames wie „Mittelschicht“ und politisch-rechtliche wie „Grundsatz“ um sich bündelt aber auch jenen der „Befreiung“. Zugleich entsteht 1992 um den Frame „Nation“ eine Verbindung mit Frames wie „Mode“ und „Geschmack“, „Kunstsinn“, „Kulturelle Entwicklung“. Damit öffnen sich die Verbindungen die der Frame „Nation“ eingeht im Gegensatz zur Situation im Jahr 1991: Im jahresspezifischen Rhizom finden sich keine solchen typischen Bezüge: „Nation“ verbindet sich mit „Herrschen“ und „Politik“. Darin zeigt sich eine Wandel der Konstruktion des Nationalen von einer auf politischem Handeln gründenden staatlichen Einheit (1991) hin zu einer stärker über kulturelle Werte definierten nationalen Gemeinschaft (1992). Zugleich macht das Rhizom Erfahrungsmöglichkeit der Nation und ihrer Wiedervereinigung auf der Ebene persönlicher sinnlicher Konsumerfahrung sichtbar.
Web-Monitoring
Die dargestellten Methoden spielen auch in der sogenannten Sicherheitsinformatik im Bereich Webmonitoring eine Rolle. Veränderungen in den Aktivitätsmustern von Usern und im Themenspektrum von Online-Diskussionsforen können so aufgespürt und auf Kritikalität hin untersucht werden.
Zum Nachlesen
Das Preprint zum Aufsatz zur ZEIT-Analyse ist online verfügbar.
Weitere Analysen zum ZEIT-Archiv auf diesem Blog:
- Das ökonomische 9/11: Fnord in der ZEIT im Verhältnis zum DAX
- Metasprachliche markierte Ausdrücke in der ZEIT im Jahr 2011 und eine kleine Geschichte der BRD in Wörtern
Darüber lacht Fefe: Sprachliche Marker für Emotionen im Dienst der Ideologieerkennung
Liebe Freunde der Sicherheit,
geschriebene Sprache ist oft vieldeutiger als gesprochene Sprache, weil sie ohne prosodische Merkmale auskommen muss und wir obendrein weder Gestik noch Mimik der Schreibenden sehen. Um Aussagen zu vereindeutigen benutzen aber viele Online-Schreiberinnen und -Schreiber Marker für Emotionen. Für Linguisten sind solche Marker sehr interessant, denn man kann versuchen, mit ihrer Hilfe Modelle zu trainieren, die z.B. die automatische Identifizierung von Ironie in Texten ermöglichen. Sicherheitsinformatiker finden solche Marker aber auch sehr praktisch, denn man kann mit ihrer Hilfe noch besser messen, was Menschen zu bestimmten Themen denken.
Besonders fleißig werden solche Marker in Fefes Blog verwendet. Wenn Fefe sich über etwas oder jemanden lustig macht, setzt er oft ein „muhahaha“, ein „HAHAHA“ oder ein „Bwahahaha“ hinzu. Der folgende Kollokationsgraph zeigt, worüber Fefe lacht (auch als zoombares PDF):

Kollokationsgraph, der die Kollokationen zu den primären Kollokatoren von Lach-Indikatoren in Fefes Blog visualisiert
Im Bereich mit der größten Dichte finden sich Wörter wie „USA“, „Deutschland“, „Polizei“, „deutsch“, „Amis“, die für diejenigen, die keine Lust oder keine Zeit zum Lesen haben, Rückschlüsse auf Fefes Einstellungen zu deutschen Staatsorganen und zu den USA haben.

Kollokationsgraph zu Lach-Markern in Fefes Blog (Ausschnitt)
Doch worüber ärgert sich Fefe? Erstellt man anhand jener Blogposts, in denen das Akronym „WTF“ auftritt, einen Kollokationsgraphen, dann erhält man folgendes Ergebnis (auch als zoombares PDF):

Kollokationsgraph anhand von Posts mit „WTF“ in Fefes Blog
Wie der folgende Ausschnitt zeigt, ist ein besonders häufiges Lemma mit vielen signifikanten Kollokatoren das Lemma „Euro“. Offenbar ärgert sich Fefe besonders oft über sinnlose Ausgaben.

Kollokationsgraph anhand von Texten mit „WTF“ in Fefes Blog (Ausschnitt)
Spaßeshalber habe ich auch noch einmal visualisiert, was Fefe dazu motiviert, Popcorn zu fordern / bereitszustellen / zu bevorraten. Popcorn ist bei Fefe ein Marker für Schadenfreude. (auch als zoombares PDF):

Kollokationsgraph anhand von Posts mit „Popcorn“ in Fefes Blog
Viel Spaß beim Zoomen!
UPDATE: Hier noch einmal die Grafiken im SVG-Format.
Breivik’s ideological map
Liebe Freunde der Sicherheit,
so wie viele seiner Vorgänger hat der Terrorist Anders Behring Breivik viel Text hinterlassen. Terrorismus ist Kommunikation. Terroristen handeln im Wissen, dass ihre Tat das System nicht umstürzen wird. Terroristische Akte wollen vielmehr Aufmerksamkeit auf eine Botschaft lenken und ihr zugleich Nachdruck verleihen. Selten spricht der Terrorakt jedoch für sich selbst. Der Terrorakt eröffnet vielmehr einen Interpretationsraum, durch den ganz unterschiedliche Wege führen können. Terroristen schreiben Texte, um diesen Raum zu verengen. Mit diesen Texten wollen sie die Interpretationsmacht über ihre Tat behaupten. Zugleich wollen sie uns zeigen, dass sie keine Terroristen sind, die nur Schrecken (lat. terror = „Schrecken“) verbreiten wollen. Sie wollen uns zeigen, dass ihr Ziel nicht die Einschüchterung durch sinnlose Gewalt ist, sondern dass sie eine politische Agenda haben, die auf der Basis rationaler Analysen und stringenter Argumente ihr Vorgehen rechtfertigt. Damit Terrorismus erfolgreich ist, braucht er Medien, die die Aufmerksamkeit auf seine Taten lenken und seine Rechtfertigungen reproduzieren. Deshalb haben alle Terroristen eine Medienstrategie. Deshalb schrieb Breivik sein Manifest „2083: A European Declaration of Independence“ und wählte das Internet für dessen Verbreitung. Das ist eine Möglichkeit, die Dinge zu sehen.

Breivik's ideological map
Eine andere Möglichkeit ist mir bei der Lektüre verschiedener Blogeinträge, vor allem zweier sehr anregender Texte von Michael Seemann, in den Sinn gekommen. In „Breivik, Queryology und der Weltkontrollverlust“ erklärt er queryologisch, wie sich der Einzeltäter sein geschlossenes Weltbild zurechtfiltern konnte. Mindestens ebenso interessant in diesem Kontext ist jedoch der Blogeintrag „Warum wir Dinge ins Internet schreiben“. Darin deutet mspr0 das Hinterlassen von Datenspuren im Netz als Möglichkeit sich unsterblich zu machen. Denn durch die Analyse dieser Datenspuren werde es in naher oder ferner Zukunft möglich, eine Persönlichkeit zu simulieren. Ins Internet schreiben, sich im Internet bewegen sei daher eine Art „Mindupload“.
Anders Behring Breivik muss damit gerechnet haben, während seiner Tat zu sterben, zumindest wird er es einkalkuliert haben. Ganz sicher aber ist er davon ausgegangen, für sehr lange Zeit sein Dasein im Gefängnis zu fristen. Wer sein Leben für eine Idee einsetzt, der will seine Identität mit der Idee verschmelzen und ihr Unsterblichkeit verleihen. Das Manifest „2083: A European Declaration of Independence“ ist Breiviks Mindupload. Simulieren können (und wollen) wir es nicht, aber visualisieren können wir es.
Die Grafik als zoombares PDF: breivik_ideological_map
Kollokationsgraphen und Ideologieerkennung am Beispiel der Sprache des militanten Islamismus
Liebe Freunde der Sicherheit,
heute möchte ich euch zeigen, wie man Kollokationen dafür benutzen kann, Schemata, Einstellungen oder Ideologien in Texten zu erkennen und zwar am Beispiel des militanten Islamismus. Wer noch nicht weiß, was Kollokationen sind, sollte in einem frühreren Artikel nachlesen.
Kollokationsgraphen
Kollokationen lassen sich als Graphen visualisieren. Was sind Graphen? Nach einer einfachen Definition sind Graphen Mengen von Punkten, zwischen denen Linien verlaufen. Sie dienen der Visualisierung von Zusammenhängen, wobei die Knoten meist Entitäten oder Konstrukten entsprechen und die Kanten Relationen. Im Fall von Kollokationsgraphen sind die Punkte Basen oder Kollokationen und die Kanten stehe für „ist Kollokation von“.
Kollokationsgraphen sind also Visualisierungen von in einem Textkorpus häufig auftretenden Wortverbindungen. Visualisierungen braucht man vor allem dann, wenn man eine große Menge von Daten hat, die man mit traditionellen Darstellungsformen wie Listen oder Tabellen nicht mehr überblicken kann. Die Kollokationen zu einem Wort lassen sich natürlich noch leicht in einer Liste zusammenfassen. Berechnet man aber die Kollokationen zu allen Wörtern in einem Textkorpus und möchte man darüber hinaus noch wissen, welche Wörter welche Kollokationen gemeinsam haben, dann ist das mit einem durchschnittlich leistungsfähigen Gehirn nicht mehr zu schaffen.
Militant islamistische Einstellungen in einem Diskussionsforum
Möchte man nun zum Beispiel anhand von Kollokationen untersuchen, welche Autorinnen und Autoren militant islamistische Positionen in einem Diskussionsforum vertreten, dann muss man zunächst wissen, welche Kollokationen als militant-islamistisch gelten sollen. Das lernt man, indem man zunächst Texte zu einem Korpus zusammenstellt, von denen man weiß, dass sie militant-islamistische Positionen vertreten. „Wissen“ heißt hier, dass jemand diese Texte tatsächlich gelesen und entsprechend bewertet haben sollte. Eigentlich ist das nichts für Korpuslinguisten, denn die sind faul und lesen ihre Texte nicht mehr. Zum Glück gibt es aber den Bundesverfassungsschutz, der uns hier die Arbeit abnimmt. Er hat zum Beispiel die deutsche Webseite der Islambrüderschaft als militant extremistisch eingestuft.
Wir laden uns also sämtliche Texte auf der Seite der Islambrüderschaft herunter, bauen ein hübsches Korpus daraus und berechnen für jedes Lemma die Lemmakollokationen. Am besten vergleichen wir die Liste noch mit einer Kollokationsliste eines nicht-extremistischen Referenzkorpus und streichen all jene Kollokationen, die nicht exklusiv im Islambrüderschaft-Korpus vorkommen. Nun haben wir eine Liste von Kollokationen, die für die Sprache des militanten Islamismus als typisch gelten können.
Als nächstes laden wir uns ein Diskussionsforum herunter und bilden autorenspezifische Korpora, d.h. wir fassen alle Posts von einem Nick zu einem Korpus zusammen. Auch hier berechnen wir zu jedem vorkommenden Lemma die Kollokationen.
Visualisierung militant-islamistischer Einstellungen
Nun kann man für jede autorenspezifische Kollokationsanalyse einen eigenen Kollokationsgraphen berechnen. So werden Wörter, die in den einzelnen Posts häufig miteinander auftreten, sichtbar gemacht. Interessant wird es für die Freunde der Sicherheit dann, wenn man jene Wortverbindungen, die sich auch bei der Islambrüderschaft finden, in den autorenspezifischen Graphen hervorhebt.
Ich habe das mal mit einem Diskussionsforum durchgerechnet, das vom Verfassungsschutz als islamistisch eingestuft wird, wenn auch nicht als militant-islamistisch. Wer wissen möchte, um welches Forum es sich handelt, kann mir gerne eine Mail schicken. Ich werde aber die Nicks nicht verraten. Das Forum ist sehr umfangreich und hat ca. 100 Mio laufende Wortformen.
Im Folgenden seht ihr einen Kollokationsgraphen von einem User, den wir als nicht militant-islamistisch einstufen würden. Es zeigen sich nur wenige typische Wortverbindungen, die auch typisch für die Islambrüderschaft sind. Diese sind im Graphen rot markiert.

Autorenspezifischer Kollokationsgraph; Quelle: islamistisches Diskussionsforum
Auch im Kollokationsgraphen eines zweiten Users sind Wortverbindungen, die als Indikatoren einer militant-islamistischen Gesinnung gelten können, nur in geringer Zahl vertreten.

Autorenspezifischer Kollokationsgraph; Quelle: islamistisches Diskussionsforum
Anders ist es bei den Posts zu einem dritten Nick. Hier sind sehr viele Kollokationen rot markiert und dies an fast allen Verdichtungspunkten des Graphen. Die Autorin oder der Autor zeigen also in vielen Themenbereichen (denn als solche lassen sich die Verdichtungsbereiche interpretieren) ähnliche sprachliche Muster wie in den Texten der Islambrüderschaft. Die Freunde der Sicherheit würden sich bei diesem Befund die Texte wohl noch einmal genauer anschauen.

Autorenspezifischer Kollokationsgraph; Quelle: islamistisches Diskussionsforum
Natürlich könnte man das Verfahren noch verfeinern, indem man beispielsweise die extrahierten militant-islamistischen Kollokationen inhaltlich gewichtet. Aber das ginge nun wirklich zu weit für einen kurzen Blog-Eintrag.
Sicher kann man bezweifeln, ob Kollokationen und Kollokationsnetze wirklich die hermeneutische Lektüre von Texten zu ersetzen. Aber das hieße, das heuristische Potenzial der angewandten Korpuslinguistik misszuverstehen. Denn sie will nicht hermeneutische Lektüren ersetzen. Sie entwickelt Kategorien und Modelle nach eigener Logik, deren Brauchbarkeit sich daran bemisst, ob sie im Rahmen konkreter Anwendungen einen Nutzen haben.