Ich hatte mein erstes Mal -> mein erstes Mal mit # -> nahm mich in den Arm -> fragte er mich ob ich -> wir bei ihm zu Hause -> seine Eltern nicht da waren -> kam er auf mich zu -> mich zu küssen und ich -> legten uns auf sein Bett -> fragte mich was los sei -> noch nie einen Freund gehabt -> zogen wir uns gegenseitig aus -> Wir küssten uns leidenschaftlich und -> Dann zog ich ihm seine -> Er schaute mich an und -> schaute mich an und fragte -> an und fragte ob ich -> mit ihm schlafen wolle und -> Er holte ein Kondom aus -> Dann drang er vorsichtig in -> er vorsichtig in mich ein -> Er fragte mich ob ich -> Als er merkte dass ich -> nahm mich in den Arm -> seit # Jahren zusammen und
Diese Phrasen bleiben von einer Geschichte vom „Ersten Mal“, wenn man von ihr das Vereinzelnde, Individualisierende wegnimmt und nur jene Teile der sprachlichen Gestaltung übrig lässt, die auch in anderen Geschichten zum gleichen Thema häufig vorkommen.
Wenn wir unseren Alltag erzählen, dann bedienen wir uns kulturell geprägter Muster. Diese Narrative sind sozial akzeptierte Interpretationsmuster, die unsere Wahrnehmung und Darstellung von Zusammenhängen überhaupt erst ermöglichen, aber gleichzeitig auch begrenzen. Obwohl sie höchst Persönliches und Individuelles zu codieren vorgeben, folgen auch Narrative vom „Ersten Mal“ kulturell geprägten Mustern, denen man sich mit maschinellen Methoden nähern kann. Zusammen mit Noah Bubenhofer und Nicole Müller habe ich 3376 Geschichten vom „Ersten Mal“ auf geschlechtsspezifische Unterschiede hin untersucht.
Sämtliche Geschichten wurden auf den Internet-Plattformen rockundliebe.de (2094 Erzählungen), Erstes-Mal.com (385 Erzählungen) und planet-liebe.de (897 Erzählungen) gesammelt. Die Webseiten wurden automatisiert heruntergeladen, die Texte extrahiert, mit Metainformationen (Alter beim Ersten Mal und Geschlecht) versehen, mit Hilfe des TreeTagger lemmatisiert und mit Part-of-speech-Informationen annotiert. Zusätzlich wurden alle Zahlen durch ein Raute-Symbol ersetzt. Insgesamt umfasst das Korpus 1.886.588 laufende Wortformen. Im Hinblick auf die Dimension Geschlecht ist das Korpus ungleich verteilt: rund 73% der Geschichten stammen von Frauen, nur rund 27% von Männern. Geschichten von Frauen waren mit durchschnittlich 567.9 Wörtern um rund 33 Wörter länger als die von Männern (534.5). Das Durchschnittsalter beim Ersten Mal, wie es von den Autorinnen und Autoren angegeben wurde, lag bei Frauen bei 15.8, bei Männern bei 16.8 Jahren.
Als Analysekategorien dienten uns die Distribution und Verkettung von n-Grammen. Die folgende Tabelle zeigt einen Vergleich der für das jeweilige Korpus typischsten n-Gramme:
| Männer-Korpus |
Frauen-Korpus |
| llr |
n-gram |
f(1) |
f(2) |
llr |
n-gram |
f(1) |
f(2) |
| 145,33 |
fragte sie mich ob ich |
0 |
54 |
80,84 |
drang er in mich ein |
134 |
0 |
| 88,81 |
fragte ich sie ob sie |
0 |
33 |
77,82 |
ob ich mit ihm schlafen |
129 |
0 |
| 75,36 |
drang ich in sie ein |
0 |
28 |
68,97 |
fragte er mich ob ich |
167 |
5 |
| 67,28 |
Ich fragte sie ob sie |
0 |
25 |
60,93 |
in mich ein Es tat |
101 |
0 |
| 64,59 |
drang langsam in sie ein |
0 |
24 |
60,93 |
legte er sich auf mich |
101 |
0 |
| 64,59 |
setzte sie sich auf mich |
0 |
24 |
47,66 |
legte sich auf mich und |
79 |
0 |
| 64,59 |
und zog es mir ueber |
0 |
24 |
47,66 |
und drang in mich ein |
79 |
0 |
| 61,9 |
setzte sich auf mich und |
0 |
23 |
45,85 |
nahm mich in den Arm |
76 |
0 |
| 59,21 |
sie sich auf mich und |
0 |
22 |
44,64 |
und legte sich auf mich |
74 |
0 |
| 56,52 |
ob ich mit ihr schlafen |
0 |
21 |
44,04 |
fing er an mich zu |
73 |
0 |
| 53,83 |
Sie fragte mich ob ich |
0 |
20 |
43,43 |
er sich auf mich und |
72 |
0 |
| 53,83 |
in sie ein Es war |
0 |
20 |
42,83 |
in mich ein Es war |
71 |
0 |
| 53,83 |
mir ein Kondom ueber und |
0 |
20 |
41,81 |
Er fragte mich ob ich |
123 |
6 |
| 53,83 |
und ich fragte sie ob |
0 |
20 |
41,02 |
und zog es sich ueber |
68 |
0 |
| 51,13 |
fluesterte sie mir ins Ohr |
0 |
19 |
40,42 |
ihn in mir zu spueren |
67 |
0 |
| 51,13 |
ich fragte sie ob sie |
0 |
19 |
40,42 |
Er legte sich auf mich |
67 |
0 |
| 48,44 |
an mir einen zu blasen |
0 |
18 |
38 |
er fragte mich ob ich |
63 |
0 |
| 48,44 |
ich drang in sie ein |
0 |
18 |
38 |
mich ob ich mit ihm |
63 |
0 |
| 48,44 |
legte sich auf den Ruecken |
0 |
18 |
35,59 |
fragte mich ob ich es |
59 |
0 |
| 48,44 |
mir das Kondom ueber und |
0 |
18 |
34,38 |
Ich war mit meinem Freund |
57 |
0 |
Aus diesen Listen wird unter anderem erkennbar, dass die verbale Handlung des Fragens, oder präziser: des Einholens von Einverständnis, offenbar häufig Bestandteil von Erstes-Mal-Erzählungen sind. Ebenso zeigen sich einige wenige geschlechtsspezifische Unterschiede: etwa die Referenz auf die Dauer der Beziehung („Ich war mit meinem Freund“).
Als eine erste Annäherung an die narrative Struktur haben wir die typischen Positionen von n-Grammen in den Texten bestimmt. Hierfür haben wir alle Texte in mehrere jeweils gleich große Teile geteilt und dann untersucht, in welchen Teilen der Erzählungen die n-Gramme mit welcher Frequenz vorkommen. Die folgenden Abbildungen zeigen die Distribution einiger n-Gramme, deren Positionierung im Text geschlechtsspezifische Unterschiede aufweist. Dies sind beispielsweise n-Gramme, die sexuelle Erfahrung und Beziehungsstatus betreffen:
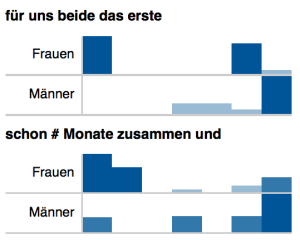
Distribution von n-Grammen in den Geschichten von Männern und Frauen (normalisierte Werte)
Während das n-Gramm „für uns beide das erste“ von Frauen im ersten und vorletzten Abschnitt am häufigsten gebraucht wird, erwähnen Männer die Tatsache, dass es für beide das Erste Mal war, erst am Ende ihrer Erzählungen. Auch das n-Gramm „schon # Monate zusammen und“ wird von Frauen dominant in den ersten Teilen ihrer Geschichten verwendet, Männer hingegen benutzen es am Ende. Eine Kontextanalyse zeigt allerdings, dass bei Verwendung des n-Gramms am Ende einer Erzählung der Geschlechtsakt der Auftakt der Beziehung war, die ihre Fortsetzung bis in die Gegenwart zum Zeitpunkt des Schreibens hat; die Verwendung des n-Gramms zu Beginn einer Erzählung stellt die Dauer der bereits bestehenden Beziehungen dar.
Größere Differenzen in der Distribution zeigen sich auch bei n-Grammen, die auf Schlüsselhandlungen im Kerngeschehen verweisen.
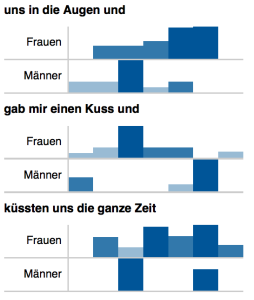
Distribution von n-Grammen in den Geschichten von Männern und Frauen (normalisierte Werte).
So sind die n-Gramme „uns in die Augen und“ und „gab mir einen Kuss und“ je gegensätzlich verteilt. Während in den Erzählungen der Frauen der Kuss am Anfang jener Abschnitte zu finden ist, die sich mit sexuellen Handlungen befassen, berichten Männer hier vorwiegend von Blicken in die Augen; Männer berichten, am Ende der sexuellen Aktivitätsphase geküsst zu werden, Frauen erzählen hier dagegen vom Austausch von Blicken. Dies könnte man so deuten, dass für Frauen mit dem Vollzug des Geschlechtsaktes eine Intensivierung der Beziehung einhergeht, die für den Mann durch die Gabe des Einverständnisses zum Geschlechtsakt durch den tiefen Blick bereits erreicht ist und sich dann im Akt manifestiert. Ein weiterer Aspekt könnte sein, dass Männer narratologisch versichern wollen, dass Einverständnis vorgelegen hat, Frauen dagegen, dass zwischen den Partner emotionale Nähe herrschte. Dies könnte ein Hinweis darauf sein, dass sich aufgrund kultureller Stereotype geschlechtsspezifische Ängste mit dem „Ersten Mal“ verbinden. In diesen Kontext passen auch die Positionsdifferenzen des n-Gramms „küssten uns die ganze Zeit“. Während das fortwährende Küssen in den Erzählungen der Männer Teil von „Vor-“ bzw. „Nachspiel“ zu sein scheint, schildern Frauen ihr Erstes Mal so, dass das Küssen Bestandteil aller Phasen des Kerngeschehens sein kann.
Unser Verfahren zur Rekonstruktion narrativer Muster auf der Makroebene kombiniert typische Musterpositionen mit n-Gramm-Verkettungen (d.h. kookkurierenden n-Grammen) und visualisiert sie als hierarchischen Graphen. Der folgende Graph (hier als PDF zum Vergrößern), der Tetragrammverkettungen in den Geschichten von Frauen illustriert, bildet die Abfolge von Mustern in der vertikalen Dimension (von oben nach unten) ab. Mehrere voneinander unabhängige narrative Muster im gleichen Abschnitt, das heißt an ähnlichen Erzählpositionen, werden nebeneinander dargestellt. In diesem Graphen sind Bereiche von geringer phraseologischer Durchdringung und Verdichtungsbereiche sichtbar.
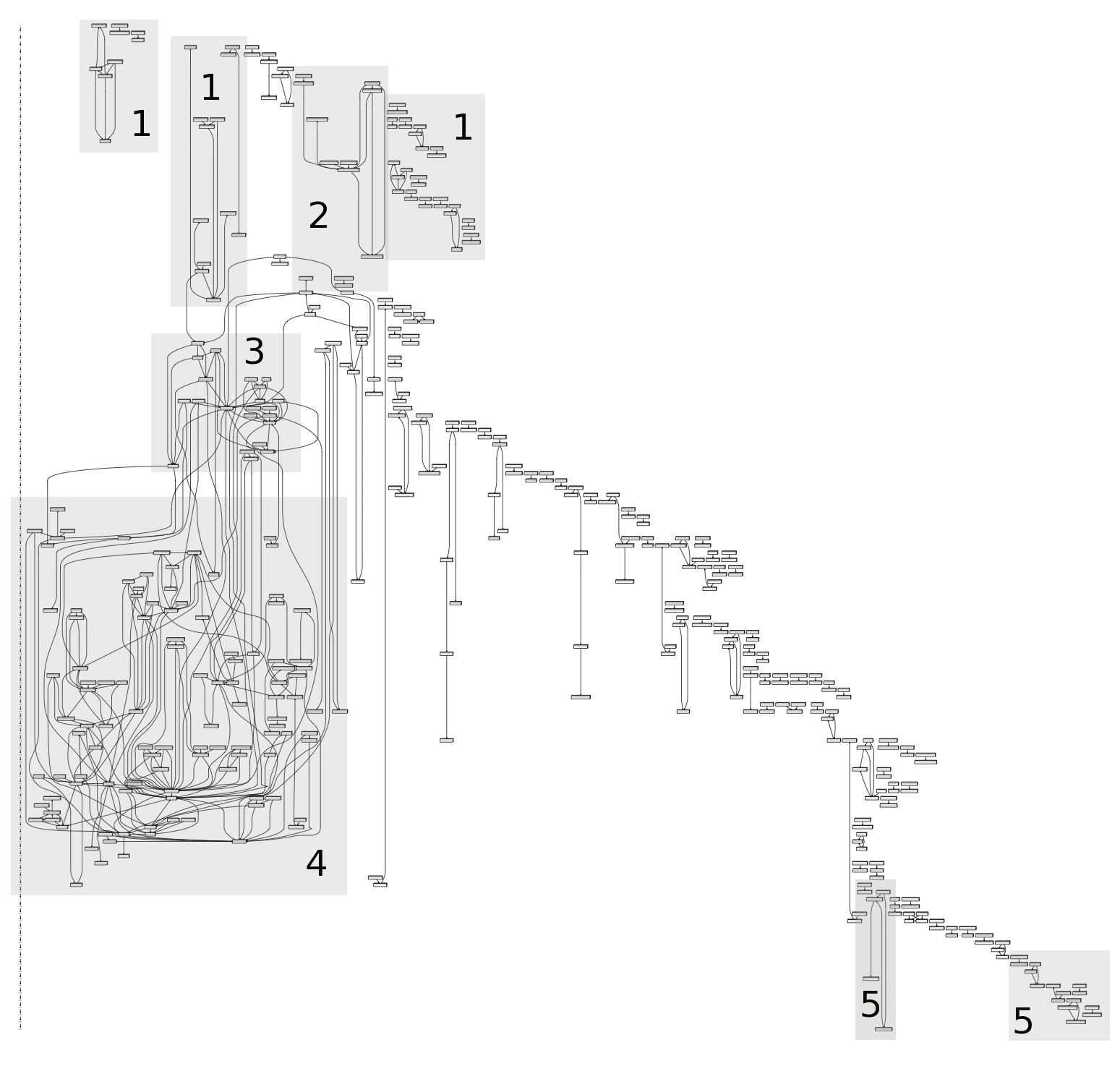
Narrationsgraph für die Erzählungen von Frauen
Muster in 1 referieren auf das Alter der Hauptpersonen der Erzählung:
Mein erstes Mal hatte – ich mit meinem Freund – hatte ich mit # – erstes Mal mit # – Bei meinem ersten Mal – ersten Mal war ich – Freund und ich waren – Ich war damals # – Ich war # und – # und er war – älter als ich und – ist # Jahre älter
Muster in 2 referieren auf die Dauer der Beziehung:
# Monate mit meinem – Monate mit meinem Freund – # Wochen mit meinem – mit mei-nem Freund zusammen – # Monate mit ihm – Monate mit ihm zusammen
Muster in 3 referieren auf die Frage des Mannes nach dem Einverständnis:
schaute mir tief in die – schaute mir lange in die – in die Augen und – fragte mich ob ich – Er fragte mich ob – mit ihm schlafen – ich es wirklich will – ich es wirklich wollte
Muster in 4 referieren auf das sexuelle Geschehen, in dem vor allem der Mann aktiv ist:
Er holte ein Kondom – Kondom aus seiner Hosentasche – aus seiner Tasche – Kondom aus seinem Nachttisch – holte ein Kondom raus – und streifte es sich – zog es sich über – sich über und drang – ganz vorsichtig in mich – langsam und vorsichtig in – langsam in mich ein – drang in mich ein – in mich ein Es – Es tat überhaupt nicht – tat überhaupt nicht weh
Muster in 5 referieren auf den gegenwärtigen Beziehungsstatus:
Und wir sind immer – immer noch zusammen und – immer noch mit ihm – noch mit ihm zusammen – Schatz ich liebe dich – liebe dich über alles
Die Umrisse der typischen Erzählung vom Ersten Mal aus der Sicht von Frauen werden anhand dieses Verfahrens gut sichtbar. Alternative Erzählstränge, die sich teilweise paral-lel zu den grau hinterlegten Teilen befinden, beziehen sich auf die Aspekte Schmerz („erst tat es ein“, „ein bisschen weh aber“, „dann war es einfach“, „es einfach nur noch“), praktische Unerfahrenheit („versuchte in mich einzudringen“) und die Evaluation („Es war ein wunderschönes“, „Es war ein unbeschreibliches“, „war ein unbeschreibliches Gefühl“, „Ich hätte nie gedacht“).
Aus dem folgenden Narrationsgraph (hier als PDF zum Vergrößern), der die Muster aus männlicher Perspektive verfasster Geschichten visualisiert, will ich nur zwei Auffälligkeiten aufgreifen.
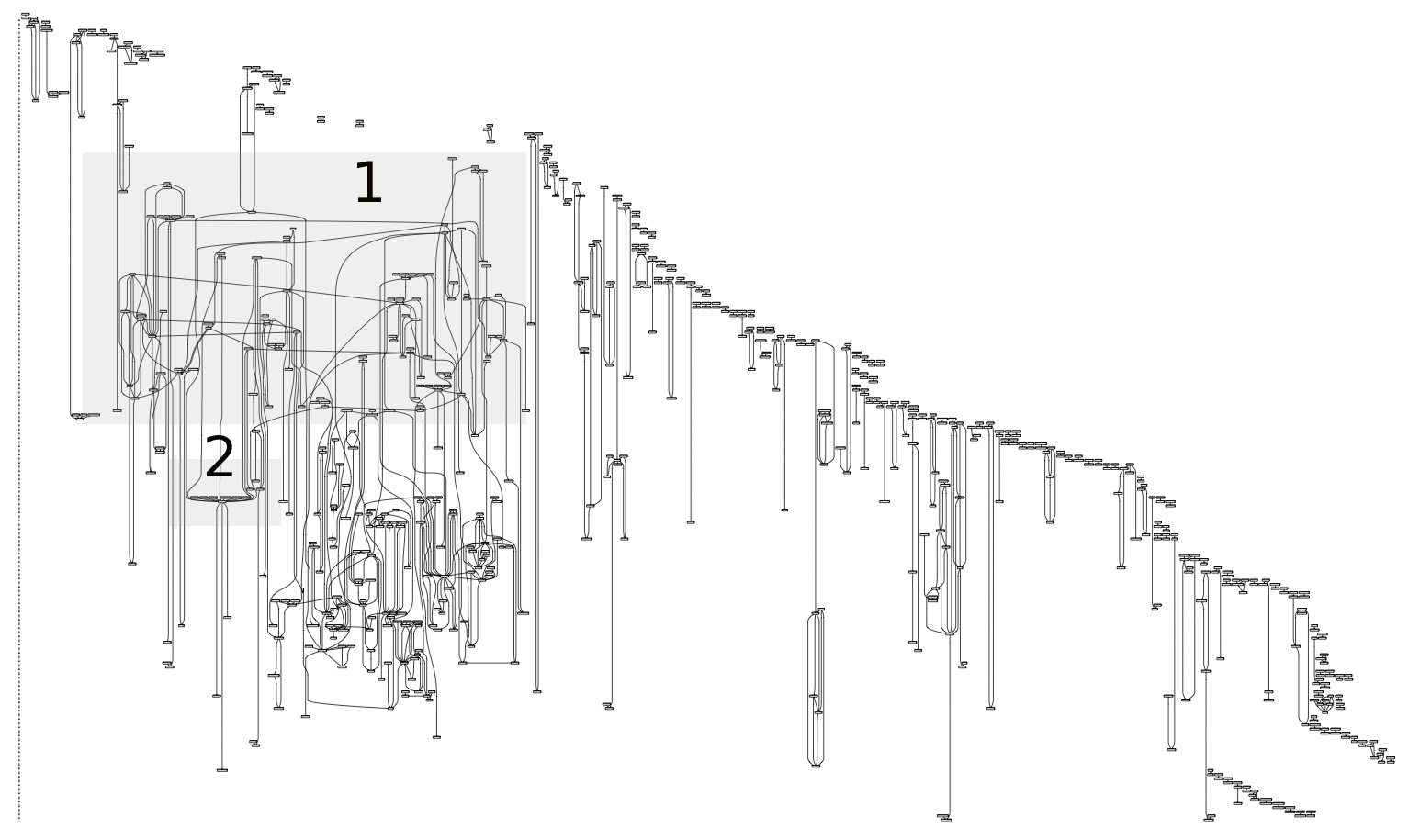
Narrationsgraph für die Erzählungen von Männern
Zum einen sind dies jene sprachlichen Muster im mit 1 bezeichneten Bereich, die auf die Einholung des Einverständnisses zum Geschlechtsakt verweisen. Hier ist es so, dass die Frage von männlicher wie weiblicher Seite kommen kann („fragte sie mich ob“, „ich fragte sie ob“). Zum anderen findet sich im mit 2 bezeichneten Bereich (siehe die nächste Abbildung) eine auffällige Verbindung mehrerer n-Gramme mit der Mehrworteinheit „Sie meinte ich solle“.
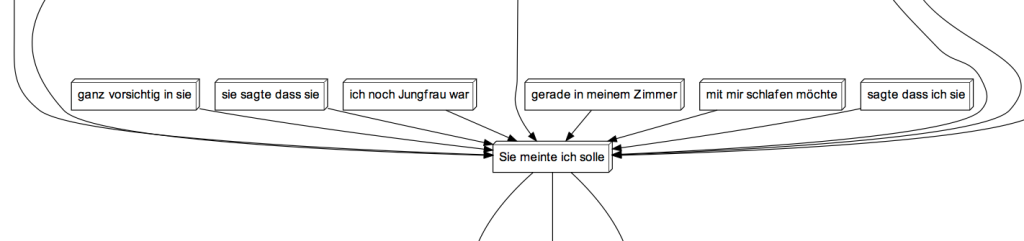
Ausschnitt aus dem Narrationsgraphen der Männer
Die Analysen zeigen, dass Geschichten vom Ersten Mal von Männern und Frauen recht ähnlich erzählt werden und zwar nicht nur im Hinblick auf das sexuelle Geschehen, sondern auch im Hinblick auf die verbalen Handlungen, die ihm vorausgehen und es begleiten. Zentraler Bestandteil typischer Erzählungen beider Geschlechter ist die verbale Verständigung über die Bereitschaft zum Geschlechtsakt und die explizite Gabe des Einverständnisses durch die Frau. Das von der Paarsoziologie als Schwellen-Wendepunkt bezeichnete Erste Mal wird also als eine durch Einverständnis der Frau legitimierte Handlungsfolge erzählt, in der der Mann mehr Handlungsmacht hat als die Frau.
Die Ergebnisse der Analyse haben wir in folgendem Artikel zusammengefasst, den es auch als Preprint gibt:
Bubenhofer, Noah / Nicole Müller / Joachim Scharloth (2014): Narrative Muster und Diskursanalyse: Ein datengeleiteter Ansatz. In: Zeitschrift für Semiotik. Band 35, Heft 3-4 (2013), S. 419-444.