Liebe Freunde der Sicherheit,
Experten begegnen uns in vielerlei Gestalt in allen Gazetten und auf allen Kanälen. Vom Finanzexperten, der uns treffsicher Auswege aus Finanzkrise weist, über den Sicherheitsexperten, der zuverlässig bei jeder Gelegenheit die Vorratsdatenspeicherung fordert, bis hin zum Spezialexperten in Fefes Blog, der als Kompetenzbombe in jedem Wissensbereich einen Volltreffer landet.
Der Experte ist ein sprachliches Konstrukt, der schon durch den bloßen Akt der Zuschreibung von Expertentum zu dem wird, als der er in den Medien erscheint: zum Experten. Dabei ist das Wort „Experte“ äußerst produktiv. Mit ihm lassen sich Unmengen an Komposita, Wörter wie „US-Hinrichtungsexperte“, „Bundesbahn-Technikexperte“, „SPD-Spielbanken-Experte“, „Humorexperte“, „American-Express-Tarifexperte“ oder Klassiker wie „Allround-Experten“, bilden. Die Journalisten von Spiegel-Print beispielsweise haben seit 1947 rund 6000 unterschiedliche Experten-Typen gekürt.
Der Siegeszug des Experten
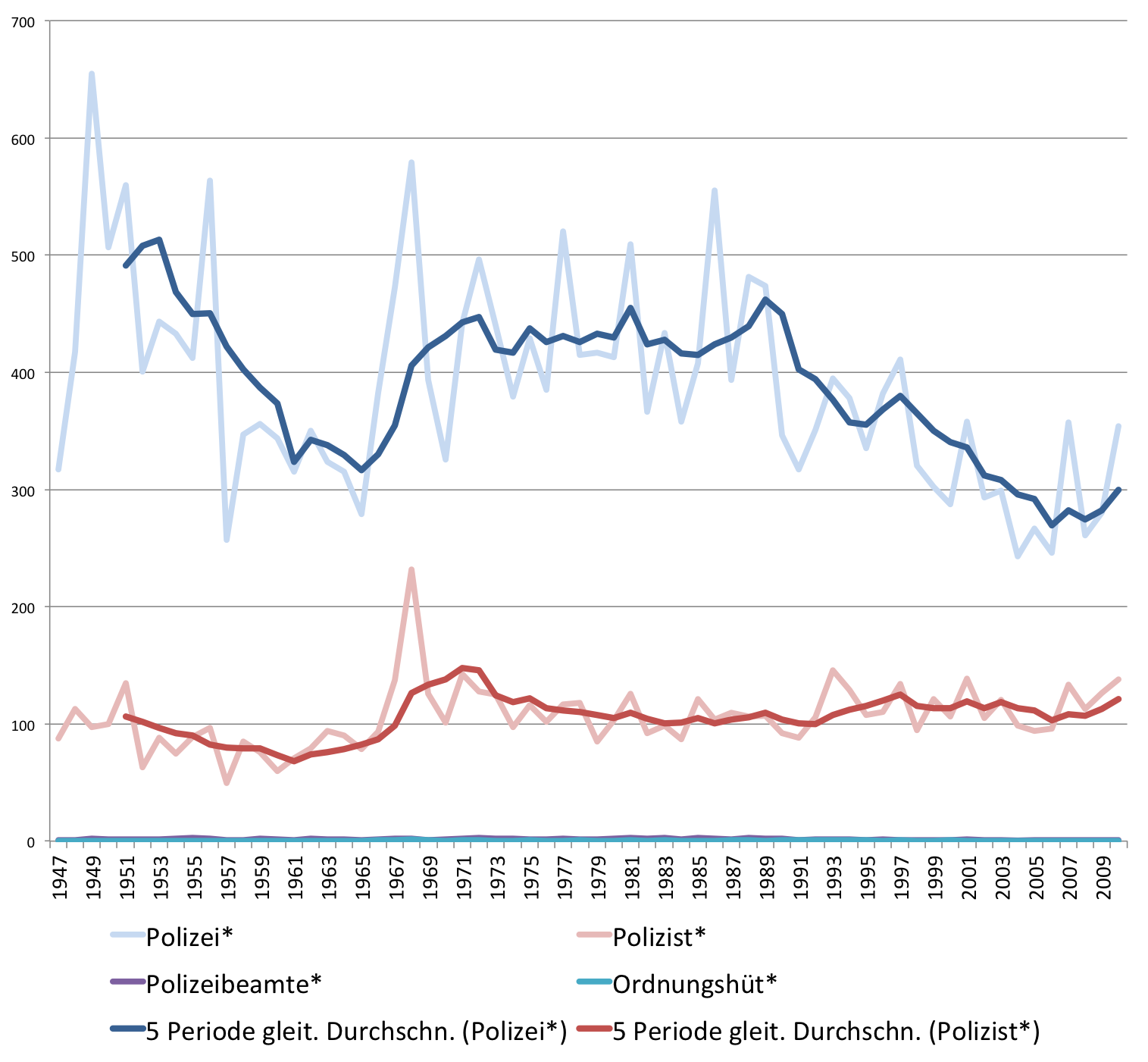
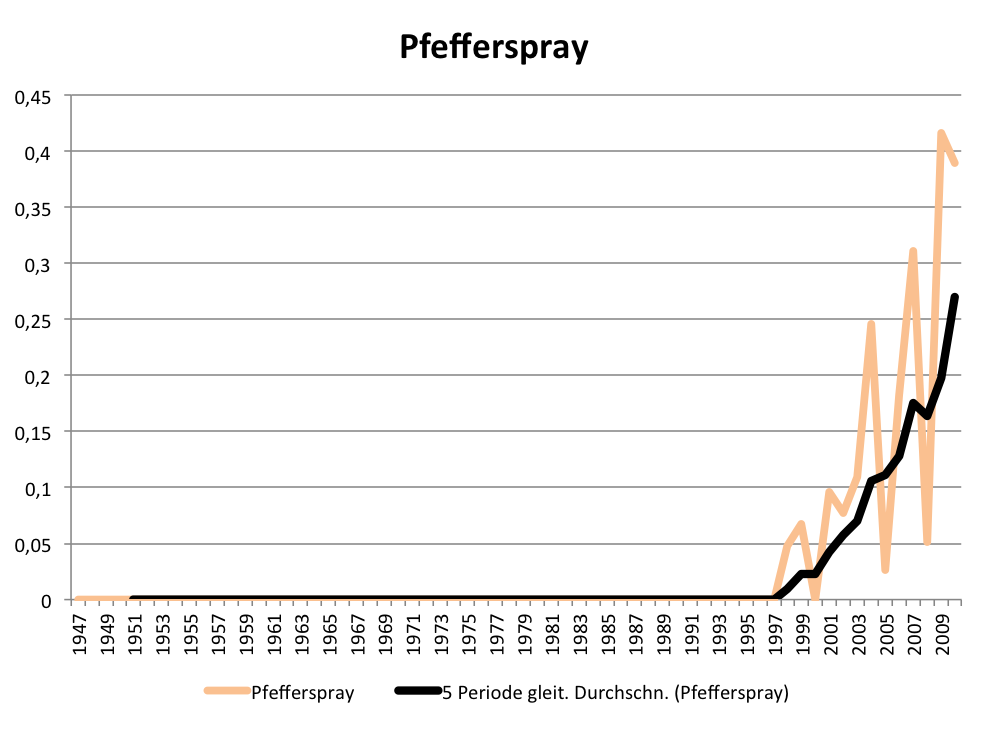
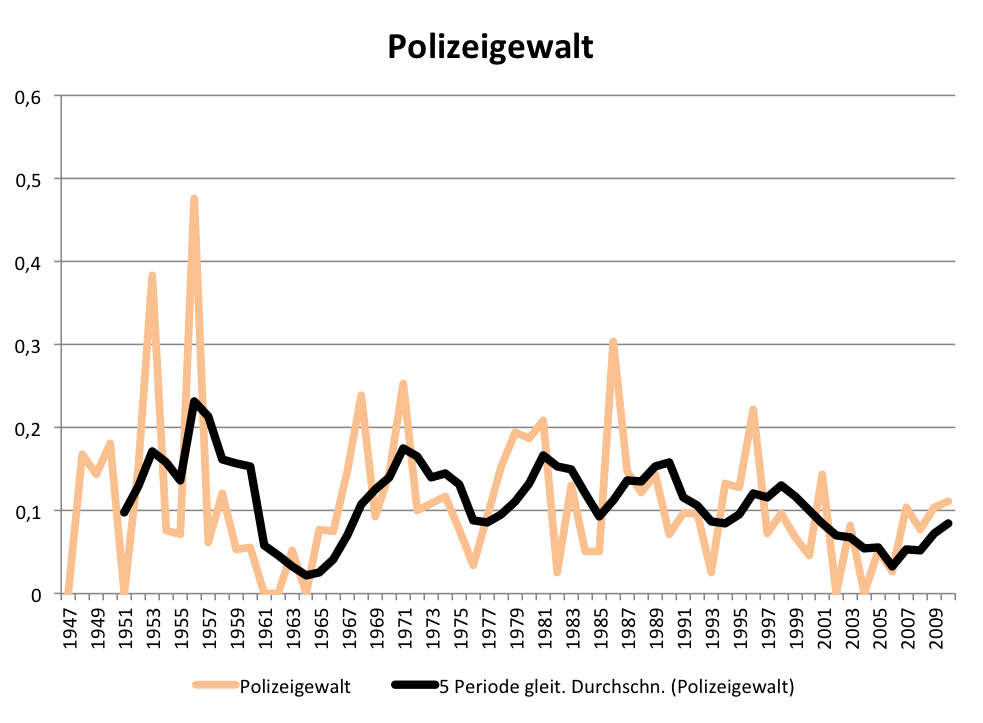
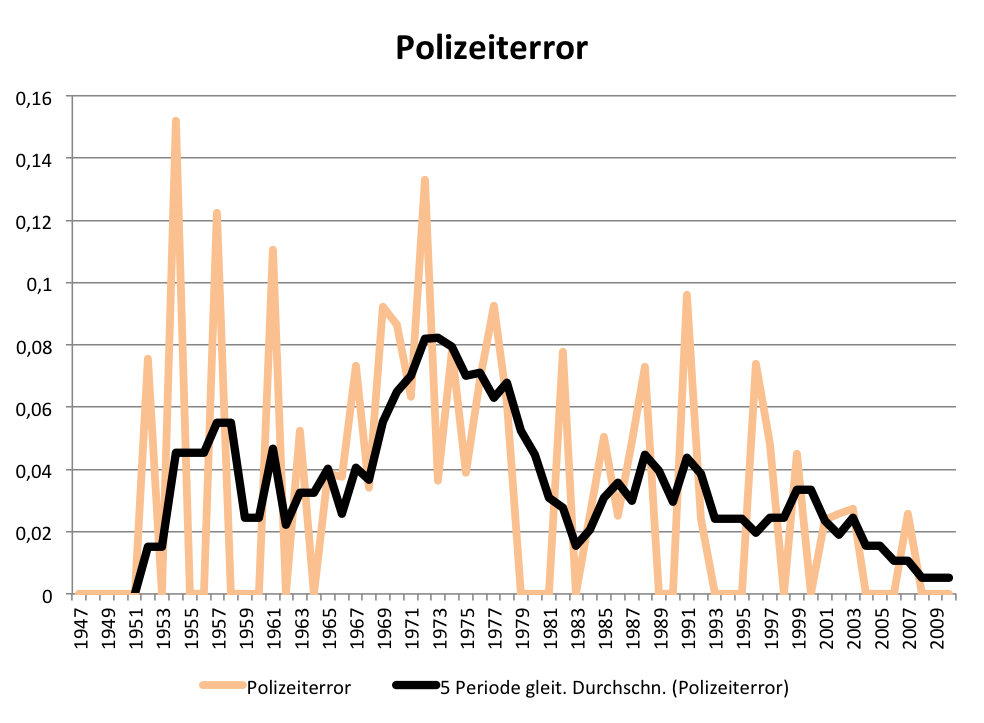
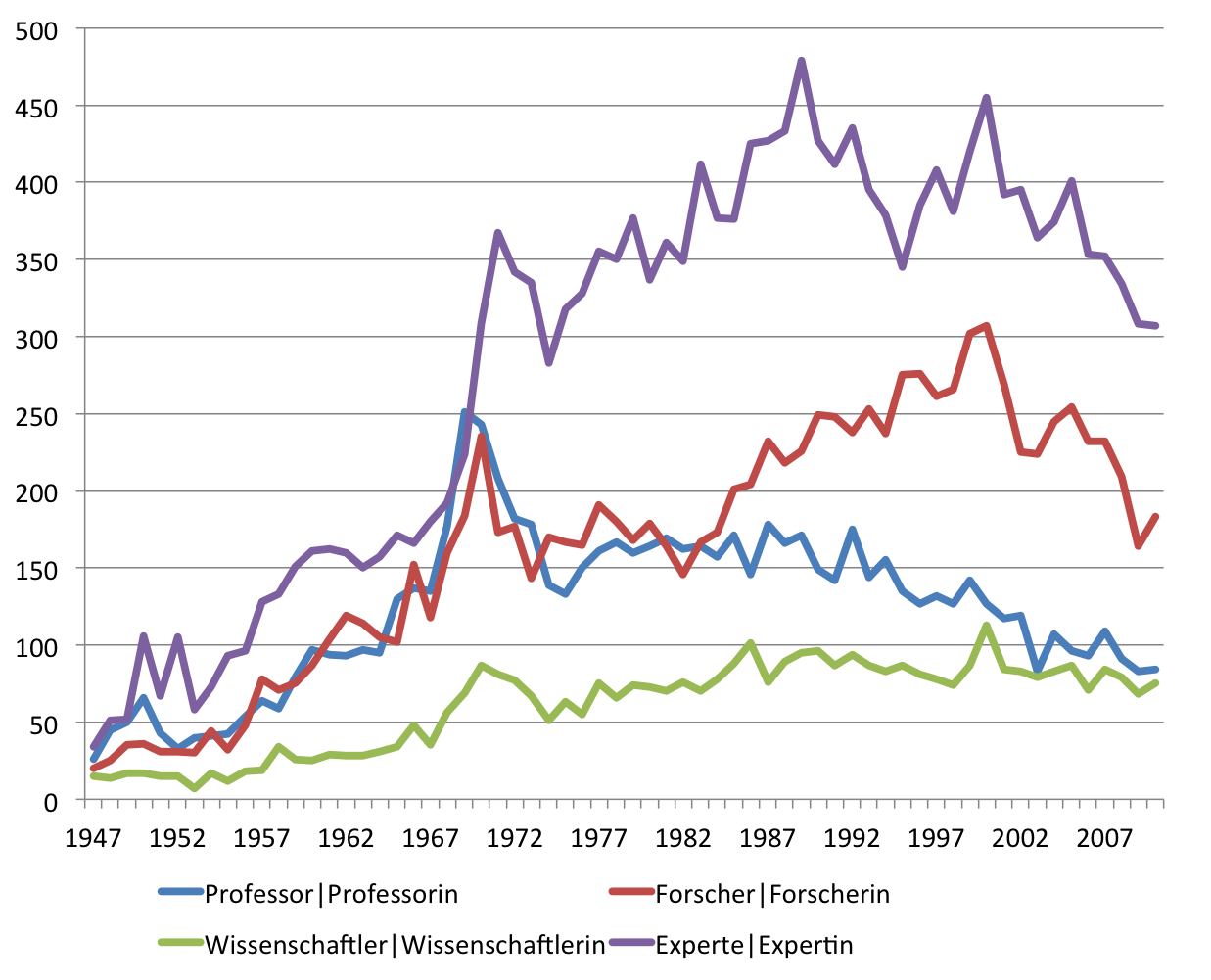
Aber seit wann gibt es den Typus des „Experten“ eigentlich in den Medien? Vergleicht man die Frequenzentwicklung des Wortes „Experte“ im gedruckten Spiegel mit der von Bezeichnungen für in akademischen Kontexten tätigen Personen wie „Wissenschaftler / Wissenschaftlerin“, „Forscher / Forscherin“ und „Professor / Professorin“, dann wird offensichtlich, dass die 68er auch am Siegeszug des Expertentums Schuld sind:

Entwicklung der relativen Frequenz der Wörter „Forscher“, „Experte“,
Wissenschaftler“ und „Professor“ und Komposita je 100.000 Wörter im SPIEGEL (print)
Nach 1968 steigt der Gebrauch des Wortes „Experte / Expertin“ und seiner Komposita sprunghaft an und verharrt dann relativ konstant auf hohem Niveau. Gleichzeitig geht der Gebrauch der Bezeichnung „Professorin / Professor“ im SPIEGEL nach 1968 dramatisch zurück, auch im Verhältnis zur Zeit vor der sogenannten Studentenrevolte, die natürlich ausführlich im SPIEGEL verhandelt wurde. Ein Trend übrigens, der sich bis in die Gegenwart fortsetzt. Die Grafik zeigt auch, dass seit den 1980er Jahren die Bezeichnung „Forscher / Forscherin“ im journalistischen Trend liegt. So produktiv im Hinblick auf die Wortbildung wie das Wort „Experte“ ist aber keines der anderen Lemmata:
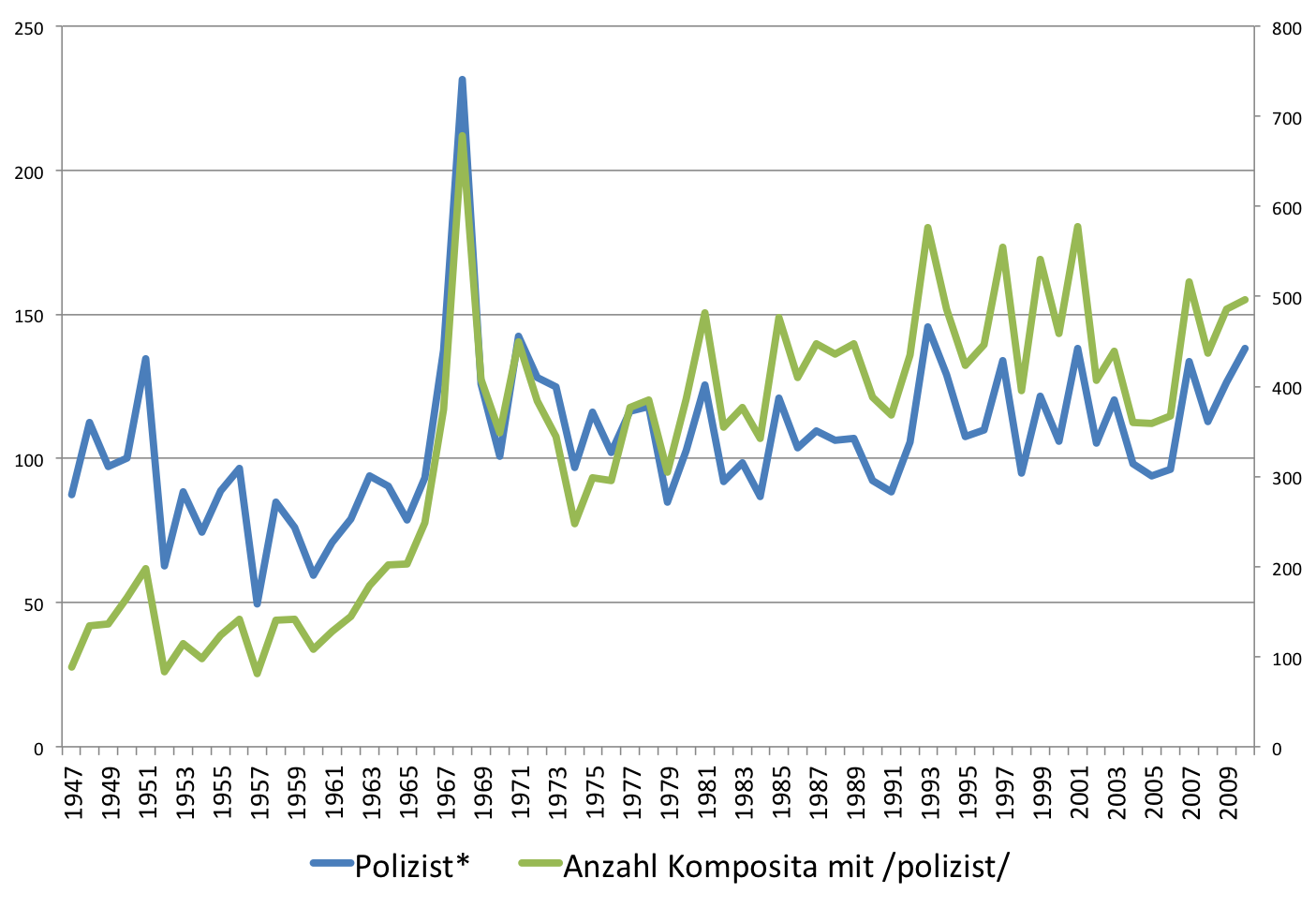
Entwicklung der Frequenz der Komposita (Types), die mit den Wörtern
„Experte“, „Forscher“, „Wissenschaftler“ und „Professor“ gebildet wurden
im SPIEGEL (print) von 1947-2010.
Die Grafik zeigt, dass die größten Veränderungen in den Jahren nach 1968 zu beobachten sind. Hier zeigt sich bei allen Bezeichnungen eine Vermehrung der Anzahl der Komposita, die mit ihnen gebildet wurden, was man als Ausdifferenzierung des Wortschatzes deuten kann. Doch nirgendwo war die Ausdifferenzierung so ausgeprägt wie bei Bezeichnungen für Experten. Die 20 am häufigsten im SPIEGEL auftretenden Experten sind:
- Finanzexperte
- Wirtschaftsexperte
- Sicherheitsexperte
- Militärexperte
- Rechtsexperte
- Verkehrsexperte
- Haushaltsexperte
- Ostexperte
- Steuerexperte
- US-Experte
- Wehrexperte
- Sozialexperte
- Umweltexperte
- Deutschland-Experte
- Agrarexperte
- Bildungsexperte
- Computerexperte
- Rüstungsexperte
- Kunstexperte
- Währungsexperte
Warum 1968?
Die Jahre um 1968 waren eine Zeit, in der Autoritäten überall in der Gesellschaft in Frage gestellt wurden. Natürlich und besonders auch das akademische „Establishment“. Hinzu kam, dass der epistemologische Konsens wegen der Politisierung der Universitäten aufgekündigt wurde: Teile der Wissenschaften wurden pauschal als „bürgerlich“ verunglimpft. Die Konsequenz war, dass der Konflikt zwischen einer „bürgerlichen“ und einer „marxistischen“ bzw. „kritisch-dialektischen“ Wissenschaftsauffassung für die Öffentlichkeit die weltanschaulich-ideologischen Implikationen wissenschaftlicher Erkenntnisse sichtbar machte und damit die Gültigkeit wissenschaftlicher Erkenntnisse relativierte. Der Experte könnte demnach als diskursives Gegengewicht zu vermeintlich „bürgerlichen“ Wissenschaftlern, aber auch als Ergebnis eines allgemeinen Autoritätsverlustes wissenschaftlicher Evidenzkonstruktionen gedeutet werden.
Experten vs. Wissenschaftler
Natürlich werden auch Wissenschaftlerinnen und Wissenschaftler in den Medien als „Experten“ bezeichnet. Dennoch zeigen sich klare Unterschiede in dem, welche Tätigkeiten Wissenschaftlern / Professorinnen / Forschern zugeschrieben werden. Im gedruckten SPIEGEL der letzten zehn Jahre zeigen sich beispielsweise folgende Muster:

Kollokationen zu den Lemmata „Forscher“, „Experte“, „Wissenschaftler“, „Professor“
im gedruckten SPIEGEL (2000-2010)
Die Tätigkeiten, mit denen Experten üblicherweise assoziiert werden sind andere als bei Personen aus dem akademischen Umfeld. Während letztere „messen“, „untersuchen“, „herausfinden“, „entschlüsseln“, „ergründen“, „entdecken“, „nachweisen“, „entwickeln“ und eben „erforschen“, treten Experten mit den Verben „schätzen“, „prognostizieren“, „warnen“, „fürchten“, „bezweifeln“ oder „empfehlen“. Der Experte kommt also immer dann ins Spiel, wenn Wissen als unsicher dargestellt, bewertet und Orientierung aus ihm abgeleitet werden soll. Die Expertise des Experten liegt also nicht im Bereich der Wissensproduktion oder Wissenssicherung, sondern im Bereich der Interpretation von Wissen und der Formulierung von Meinungen, wie mit diesem Wissen umgegangen werden soll. In Wörterbüchern freilich wird „Experte“ als Sachverständiger, Fachmann oder Kenner definiert. Es ist die Spannung zwischen vermeintlich objektiver Sachkenntnis und interessegeleiteter Meinungsproduktion, die die Bezeichnung „Experte“ in den Augen vieler fragwürdig gemacht hat.
Herzlich grüßt euer Sprachexperte Joachim Scharloth